 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVolumetric Reconstruction of Prostatectomy Specimens from Histology
Nov 29, 2024



Surgical treatment for prostate cancer often involves organ removal, i.e., prostatectomy. Pathology reports on these specimens convey treatment-relevant information. Beyond these reports, the diagnostic process generates extensive and complex information that is difficult to represent in reports, although it is of significant interest to the other medical specialties involved. 3D tissue reconstruction would allow for better spatial visualization, as well as combinations with other imaging modalities. Existing approaches in this area have proven labor-intensive and challenging to integrate into clinical workflows. 3D-SLIVER provides a simplified solution, implemented as an open-source 3DSlicer extension. We outline three specific real-world scenarios to illustrate its potential to improve transparency in diagnostic workflows and contribute to multi-modal research endeavors. Implementing the 3D reconstruction process involved four sub-modules of 3D-SLIVER: digitization of slicing protocol, virtual slicing of arbitrary 3D models based on that protocol, registration of slides with virtual slices using the Coherent Point Drift algorithm, and 3D reconstruction of registered information using convex hulls, Gaussian splatter and linear extrusion. Three use cases to employ 3D-SLIVER are presented: a low-effort approach to pathology workflow integration and two research-related use cases illustrating how to perform retrospective evaluations of PI-RADS predictions and statistically model 3D distributions of morphological patterns. 3D-SLIVER allows for improved interdisciplinary communication among specialties. It is designed for simplicity in application, allowing for flexible integration into various workflows and use cases. Here we focused on the clinical care of prostate cancer patients, but future possibilities are extensive with other neoplasms and in education and research.
Digitization of Pathology Labs: A Review of Lessons Learned
Jun 07, 2023


Pathology laboratories are increasingly using digital workflows. This has the potential of increasing lab efficiency, but the digitization process also involves major challenges. Several reports have been published describing the individual experiences of specific laboratories with the digitization process. However, a comprehensive overview of the lessons learned is still lacking. We provide an overview of the lessons learned for different aspects of the digitization process, including digital case management, digital slide reading, and computer-aided slide reading. We also cover metrics used for monitoring performance and pitfalls and corresponding values observed in practice. The overview is intended to help pathologists, IT decision-makers, and administrators to benefit from the experiences of others and to implement the digitization process in an optimal way to make their own laboratory future-proof.
Recommendations on test datasets for evaluating AI solutions in pathology
Apr 21, 2022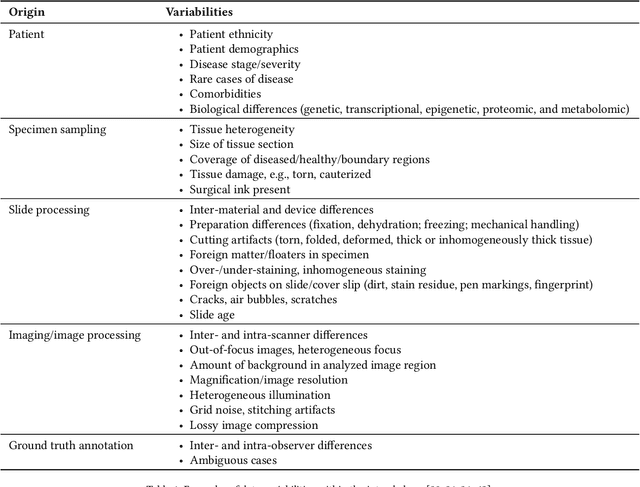
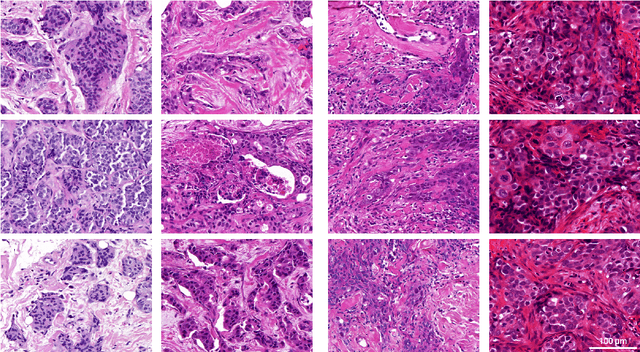

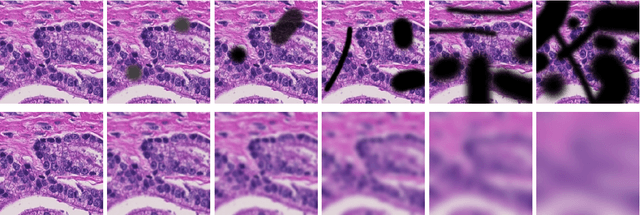
Artificial intelligence (AI) solutions that automatically extract information from digital histology images have shown great promise for improving pathological diagnosis. Prior to routine use, it is important to evaluate their predictive performance and obtain regulatory approval. This assessment requires appropriate test datasets. However, compiling such datasets is challenging and specific recommendations are missing. A committee of various stakeholders, including commercial AI developers, pathologists, and researchers, discussed key aspects and conducted extensive literature reviews on test datasets in pathology. Here, we summarize the results and derive general recommendations for the collection of test datasets. We address several questions: Which and how many images are needed? How to deal with low-prevalence subsets? How can potential bias be detected? How should datasets be reported? What are the regulatory requirements in different countries? The recommendations are intended to help AI developers demonstrate the utility of their products and to help regulatory agencies and end users verify reported performance measures. Further research is needed to formulate criteria for sufficiently representative test datasets so that AI solutions can operate with less user intervention and better support diagnostic workflows in the future.