 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJustification of Recommender Systems Results: A Service-based Approach
Nov 07, 2022With the increasing demand for predictable and accountable Artificial Intelligence, the ability to explain or justify recommender systems results by specifying how items are suggested, or why they are relevant, has become a primary goal. However, current models do not explicitly represent the services and actors that the user might encounter during the overall interaction with an item, from its selection to its usage. Thus, they cannot assess their impact on the user's experience. To address this issue, we propose a novel justification approach that uses service models to (i) extract experience data from reviews concerning all the stages of interaction with items, at different granularity levels, and (ii) organize the justification of recommendations around those stages. In a user study, we compared our approach with baselines reflecting the state of the art in the justification of recommender systems results. The participants evaluated the Perceived User Awareness Support provided by our service-based justification models higher than the one offered by the baselines. Moreover, our models received higher Interface Adequacy and Satisfaction evaluations by users having different levels of Curiosity or low Need for Cognition (NfC). Differently, high NfC participants preferred a direct inspection of item reviews. These findings encourage the adoption of service models to justify recommender systems results but suggest the investigation of personalization strategies to suit diverse interaction needs.
Using consumer feedback from location-based services in PoI recommender systems for people with autism
Apr 21, 2022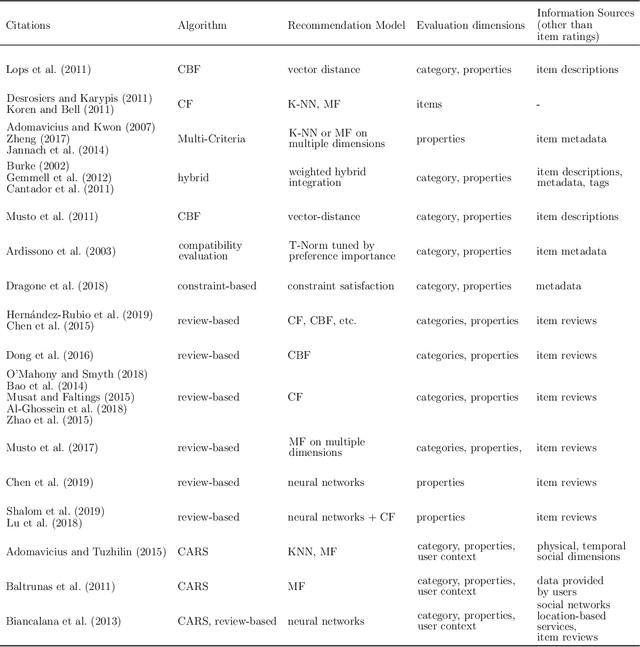
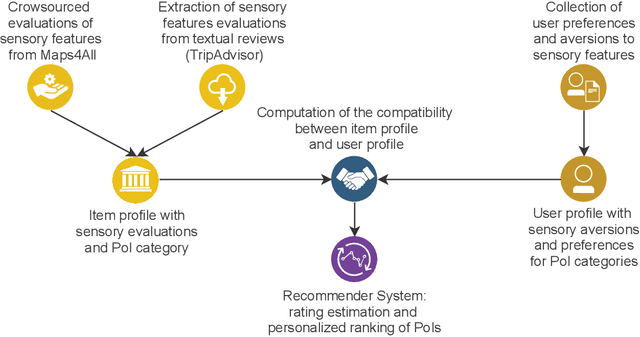
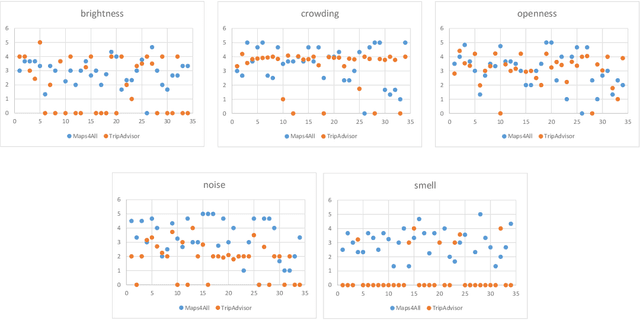
When suggesting Points of Interest (PoIs) to people with autism spectrum disorders, we must take into account that they have idiosyncratic sensory aversions to noise, brightness and other features that influence the way they perceive places. Therefore, recommender systems must deal with these aspects. However, the retrieval of sensory data about PoIs is a real challenge because most geographical information servers fail to provide this data. Moreover, ad-hoc crowdsourcing campaigns do not guarantee to cover large geographical areas and lack sustainability. Thus, we investigate the extraction of sensory data about places from the consumer feedback collected by location-based services, on which people spontaneously post reviews from all over the world. Specifically, we propose a model for the extraction of sensory data from the reviews about PoIs, and its integration in recommender systems to predict item ratings by considering both user preferences and compatibility information. We tested our approach with autistic and neurotypical people by integrating it into diverse recommendation algorithms. For the test, we used a dataset built in a crowdsourcing campaign and another one extracted from TripAdvisor reviews. The results show that the algorithms obtain the highest accuracy and ranking capability when using TripAdvisor data. Moreover, by jointly using these two datasets, the algorithms further improve their performance. These results encourage the use of consumer feedback as a reliable source of information about places in the development of inclusive recommender systems.
User and Item-aware Estimation of Review Helpfulness
Nov 20, 2020
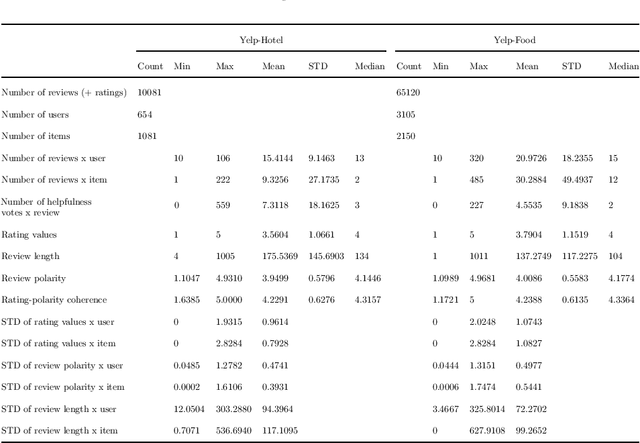

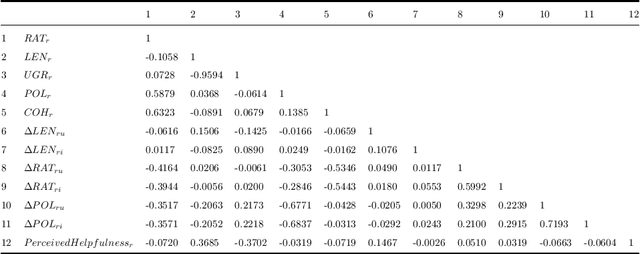
In online review sites, the analysis of user feedback for assessing its helpfulness for decision-making is usually carried out by locally studying the properties of individual reviews. However, global properties should be considered as well to precisely evaluate the quality of user feedback. In this paper we investigate the role of deviations in the properties of reviews as helpfulness determinants with the intuition that "out of the core" feedback helps item evaluation. We propose a novel helpfulness estimation model that extends previous ones with the analysis of deviations in rating, length and polarity with respect to the reviews written by the same person, or concerning the same item. A regression analysis carried out on two large datasets of reviews extracted from Yelp social network shows that user-based deviations in review length and rating clearly influence perceived helpfulness. Moreover, an experiment on the same datasets shows that the integration of our helpfulness estimation model improves the performance of a collaborative recommender system by enhancing the selection of high-quality data for rating estimation. Our model is thus an effective tool to select relevant user feedback for decision-making.
Session-aware Recommendation: A Surprising Quest for the State-of-the-art
Nov 06, 2020

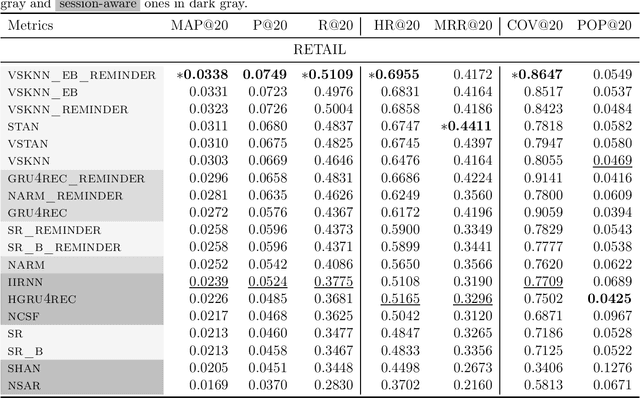
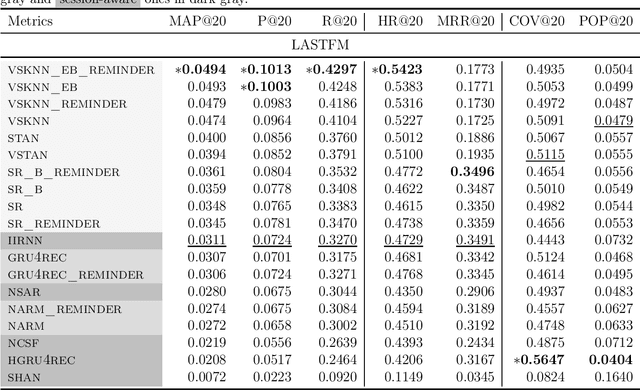
Recommender systems are designed to help users in situations of information overload. In recent years, we observed increased interest in session-based recommendation scenarios, where the problem is to make item suggestions to users based only on interactions observed in an ongoing session. However, in cases where interactions from previous user sessions are available, the recommendations can be personalized according to the users' long-term preferences, a process called session-aware recommendation. Today, research in this area is scattered and many existing works only compare session-aware with session-based models. This makes it challenging to understand what represents the state-of-the-art. To close this research gap, we benchmarked recent session-aware algorithms against each other and against a number of session-based recommendation algorithms and trivial extensions thereof. Our comparison, to some surprise, revealed that (i) item simple techniques based on nearest neighbors consistently outperform recent neural techniques and that (ii) session-aware models were mostly not better than approaches that do not use long-term preference information. Our work therefore not only points to potential methodological issues where new methods are compared to weak baselines, but also indicates that there remains a huge potential for more sophisticated session-aware recommendation algorithms.
Personalized Recommendation of PoIs to People with Autism
Apr 27, 2020
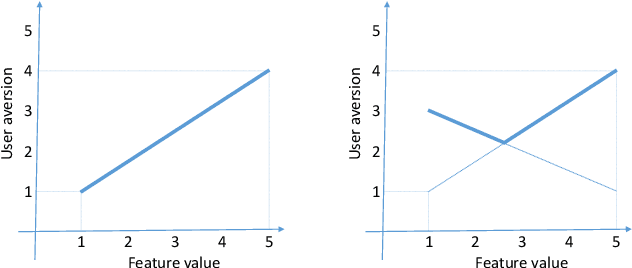
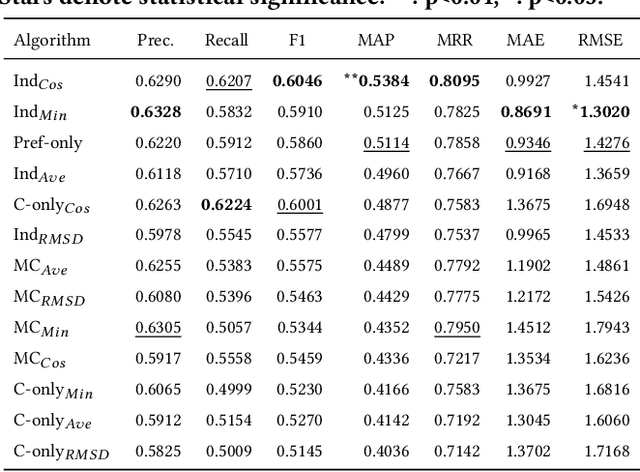
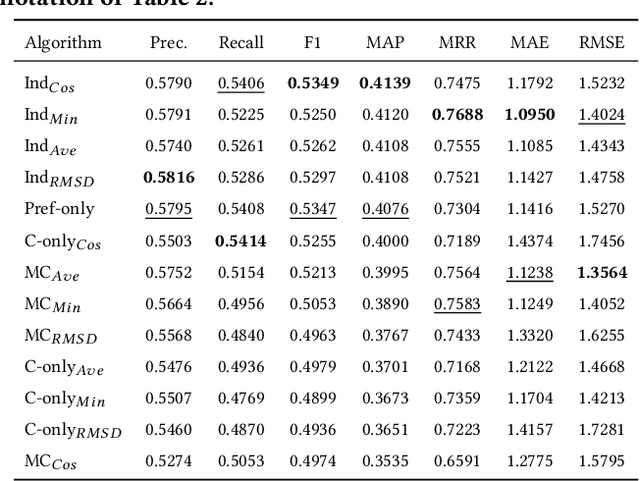
The suggestion of Points of Interest to people with Autism Spectrum Disorder (ASD) challenges recommender systems research because these users' perception of places is influenced by idiosyncratic sensory aversions which can mine their experience by causing stress and anxiety. Therefore, managing individual preferences is not enough to provide these people with suitable recommendations. In order to address this issue, we propose a Top-N recommendation model that combines the user's idiosyncratic aversions with her/his preferences in a personalized way to suggest the most compatible and likable Points of Interest for her/him. We are interested in finding a user-specific balance of compatibility and interest within a recommendation model that integrates heterogeneous evaluation criteria to appropriately take these aspects into account. We tested our model on both ASD and "neurotypical" people. The evaluation results show that, on both groups, our model outperforms in accuracy and ranking capability the recommender systems based on item compatibility, on user preferences, or which integrate these two aspects by means of a uniform evaluation model.
Impact of Semantic Granularity on Geographic Information Search Support
Apr 01, 2020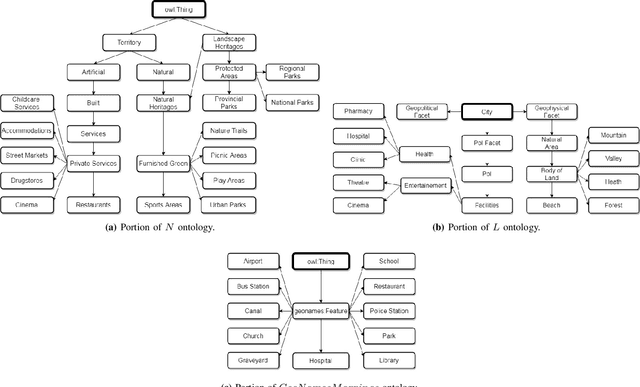
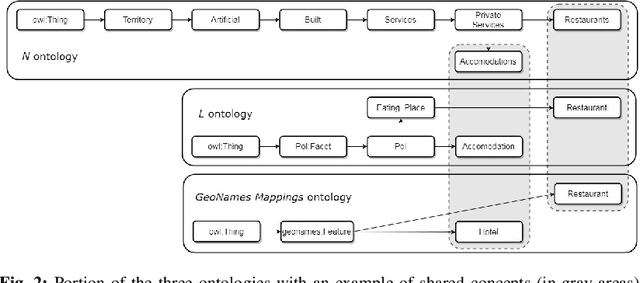
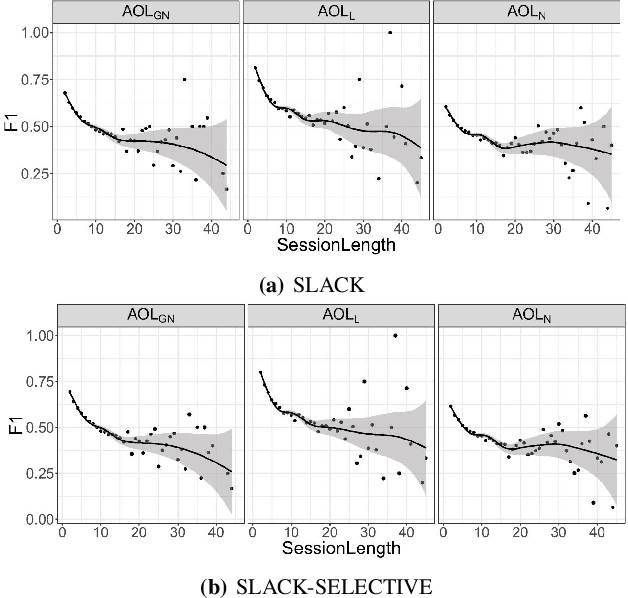
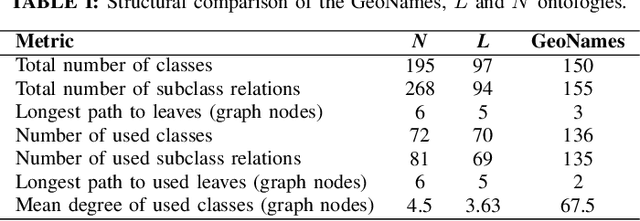
The Information Retrieval research has used semantics to provide accurate search results, but the analysis of conceptual abstraction has mainly focused on information integration. We consider session-based query expansion in Geographical Information Retrieval, and investigate the impact of semantic granularity (i.e., specificity of concepts representation) on the suggestion of relevant types of information to search for. We study how different levels of detail in knowledge representation influence the capability of guiding the user in the exploration of a complex information space. A comparative analysis of the performance of a query expansion model, using three spatial ontologies defined at different semantic granularity levels, reveals that a fine-grained representation enhances recall. However, precision depends on how closely the ontologies match the way people conceptualize and verbally describe the geographic space.
Multi-faceted Trust-based Collaborative Filtering
Mar 25, 2020
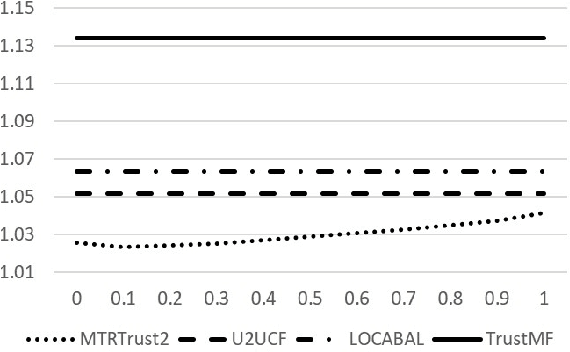

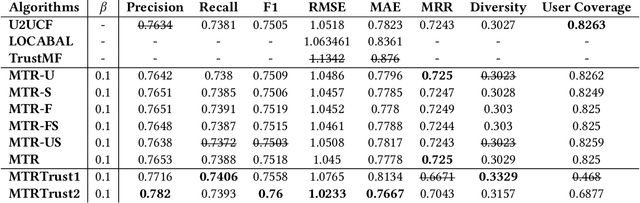
Many collaborative recommender systems leverage social correlation theories to improve suggestion performance. However, they focus on explicit relations between users and they leave out other types of information that can contribute to determine users' global reputation; e.g., public recognition of reviewers' quality. We are interested in understanding if and when these additional types of feedback improve Top-N recommendation. For this purpose, we propose a multi-faceted trust model to integrate local trust, represented by social links, with various types of global trust evidence provided by social networks. We aim at identifying general classes of data in order to make our model applicable to different case studies. Then, we test the model by applying it to a variant of User-to-User Collaborative filtering (U2UCF) which supports the fusion of rating similarity, local trust derived from social relations, and multi-faceted reputation for rating prediction. We test our model on two datasets: the Yelp one publishes generic friend relations between users but provides different types of trust feedback, including user profile endorsements. The LibraryThing dataset offers fewer types of feedback but it provides more selective friend relations aimed at content sharing. The results of our experiments show that, on the Yelp dataset, our model outperforms both U2UCF and state-of-the-art trust-based recommenders that only use rating similarity and social relations. Differently, in the LibraryThing dataset, the combination of social relations and rating similarity achieves the best results. The lesson we learn is that multi-faceted trust can be a valuable type of information for recommendation. However, before using it in an application domain, an analysis of the type and amount of available trust evidence has to be done to assess its real impact on recommendation performance.
Session-based Suggestion of Topics for Geographic Exploratory Search
Mar 25, 2020



Exploratory information search can challenge users in the formulation of efficacious search queries. Moreover, complex information spaces, such as those managed by Geographical Information Systems, can disorient people, making it difficult to find relevant data. In order to address these issues, we developed a session-based suggestion model that proposes concepts as a "you might also be interested in" function, by taking the user's previous queries into account. Our model can be applied to incrementally generate suggestions in interactive search. It can be used for query expansion, and in general to guide users in the exploration of possibly complex spaces of data categories. Our model is based on a concept co-occurrence graph that describes how frequently concepts are searched together in search sessions. Starting from an ontological domain representation, we generated the graph by analyzing the query log of a major search engine. Moreover, we identified clusters of ontology concepts which frequently co-occur in the sessions of the log via community detection on the graph. The evaluation of our model provided satisfactory accuracy results.
Empirical Analysis of Session-Based Recommendation Algorithms
Oct 28, 2019
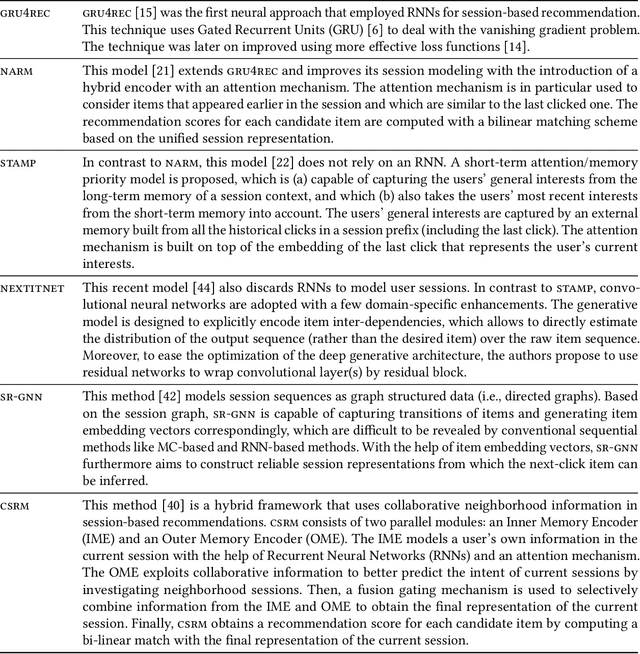
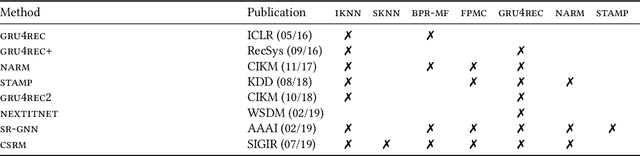
Recommender systems are tools that support online users by pointing them to potential items of interest in situations of information overload. In recent years, the class of session-based recommendation algorithms received more attention in the research literature. These algorithms base their recommendations solely on the observed interactions with the user in an ongoing session and do not require the existence of long-term preference profiles. Most recently, a number of deep learning based ("neural") approaches to session-based recommendations were proposed. However, previous research indicates that today's complex neural recommendation methods are not always better than comparably simple algorithms in terms of prediction accuracy. With this work, our goal is to shed light on the state-of-the-art in the area of session-based recommendation and on the progress that is made with neural approaches. For this purpose, we compare twelve algorithmic approaches, among them six recent neural methods, under identical conditions on various datasets. We find that the progress in terms of prediction accuracy that is achieved with neural methods is still limited. In most cases, our experiments show that simple heuristic methods based on nearest-neighbors schemes are preferable over conceptually and computationally more complex methods. Observations from a user study furthermore indicate that recommendations based on heuristic methods were also well accepted by the study participants. To support future progress and reproducibility in this area, we publicly share the session-rec evaluation framework that was used in our research.
A Compositional Model of Multi-faceted Trust for Personalized Item Recommendation
Sep 04, 2019
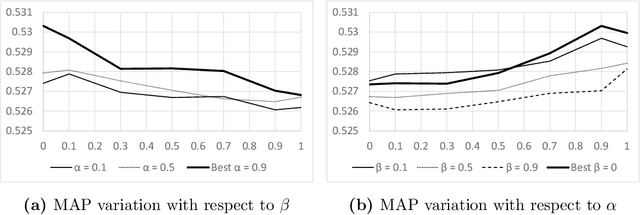
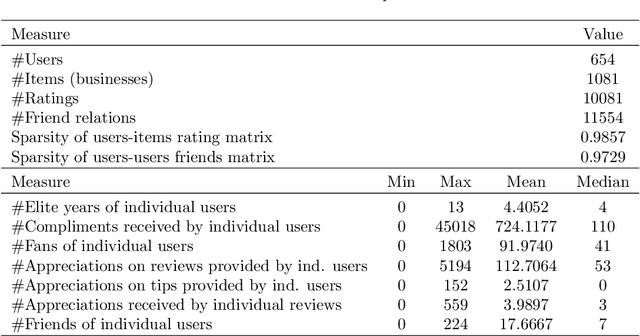

Trust-based recommender systems improve rating prediction with respect to Collaborative Filtering by leveraging the additional information provided by a trust network among users to deal with the cold start problem. However, they are challenged by recent studies according to which people generally perceive the usage of data about social relations as a violation of their own privacy. In order to address this issue, we extend trust-based recommender systems with additional evidence about trust, based on public anonymous information, and we make them configurable with respect to the data that can be used in the given application domain: 1 - We propose the Multi-faceted Trust Model (MTM) to define trust among users in a compositional way, possibly including or excluding the types of information it contains. MTM flexibly integrates social links with public anonymous feedback received by user profiles and user contributions in social networks. 2 - We propose LOCABAL+, based on MTM, which extends the LOCABAL trust-based recommender system with multi-faceted trust and trust-based social regularization. Experiments carried out on two public datasets of item reviews show that, with a minor loss of user coverage, LOCABAL+ outperforms state-of-the art trust-based recommender systems and Collaborative Filtering in accuracy, ranking of items and error minimization both when it uses complete information about trust and when it ignores social relations. The combination of MTM with LOCABAL+ thus represents a promising alternative to state-of-the-art trust-based recommender systems.