 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondition-Transforming Variational AutoEncoder for Conversation Response Generation
Apr 24, 2019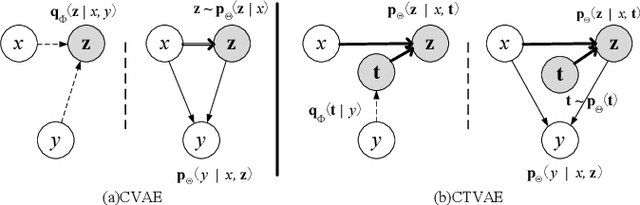

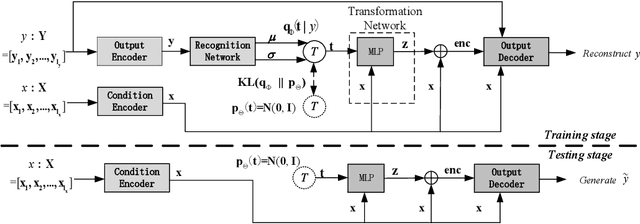
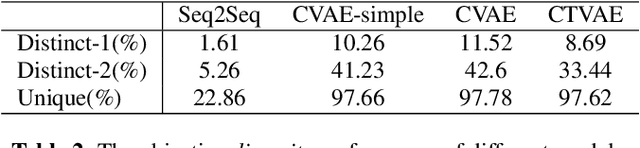
This paper proposes a new model, called condition-transforming variational autoencoder (CTVAE), to improve the performance of conversation response generation using conditional variational autoencoders (CVAEs). In conventional CVAEs , the prior distribution of latent variable z follows a multivariate Gaussian distribution with mean and variance modulated by the input conditions. Previous work found that this distribution tends to become condition independent in practical application. In our proposed CTVAE model, the latent variable z is sampled by performing a non-lineartransformation on the combination of the input conditions and the samples from a condition-independent prior distribution N (0; I). In our objective evaluations, the CTVAE model outperforms the CVAE model on fluency metrics and surpasses a sequence-to-sequence (Seq2Seq) model on diversity metrics. In subjective preference tests, our proposed CTVAE model performs significantly better than CVAE and Seq2Seq models on generating fluency, informative and topic relevant responses.