 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of Object Detection Networks for Scientific Plots
Jul 05, 2020
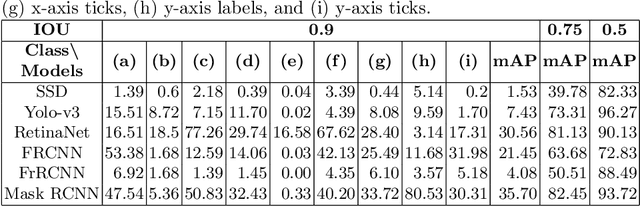


Are existing object detection methods adequate for detecting text and visual elements in scientific plots which are arguably different than the objects found in natural images? To answer this question, we train and compare the accuracy of Fast/Faster R-CNN, SSD, YOLO and RetinaNet on the PlotQA dataset with over 220,000 scientific plots. At the standard IOU setting of 0.5, most networks perform well with mAP scores greater than 80% in detecting the relatively simple objects in plots. However, the performance drops drastically when evaluated at a stricter IOU of 0.9 with the best model giving a mAP of 35.70%. Note that such a stricter evaluation is essential when dealing with scientific plots where even minor localisation errors can lead to large errors in downstream numerical inferences. Given this poor performance, we propose minor modifications to existing models by combining ideas from different object detection networks. While this significantly improves the performance, there are still 2 main issues: (i) performance on text objects which are essential for reasoning is very poor, and (ii) inference time is unacceptably large considering the simplicity of plots. Based on these experiments and results, we identify the following considerations for improving object detection on plots: (a) small inference time, (b) higher precision on text objects, and (c) more accurate localisation with a custom loss function with non-negligible loss values at high IOU (> 0.8). We propose a network which meets all these considerations: It is 16x faster than the best performing competitor and significantly improves upon the accuracy of existing models with a mAP of 93.44%@0.9 IOU.
Data Interpretation over Plots
Sep 03, 2019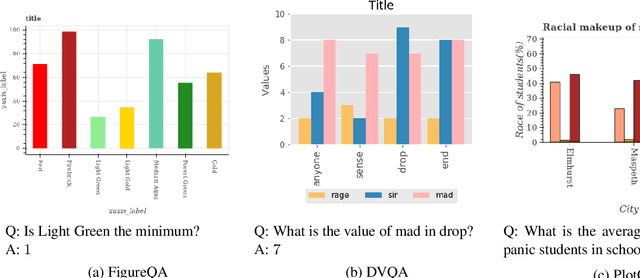
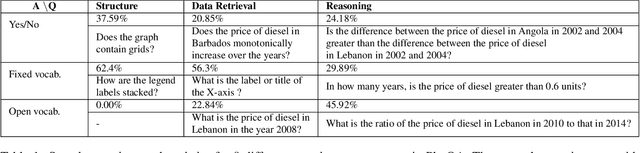

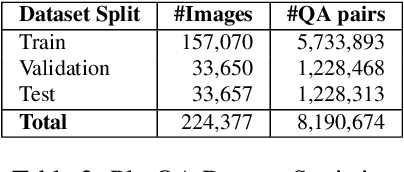
Reasoning over plots by question answering (QA) is a challenging machine learning task at the intersection of vision, language processing, and reasoning. Existing synthetic datasets (FigureQA, DVQA) do not model variability in data labels, real-valued data, or complex reasoning questions. Consequently, proposed models for these datasets do not fully address the challenge of reasoning over plots. We propose PlotQA with 8.1 million question-answer pairs over 220,000 plots with data from real-world sources and questions based on crowd-sourced question templates. 26% of the questions in PlotQA have answers that are not in a fixed vocabulary, requiring reasoning capabilities. Analysis of existing models on PlotQA reveals that a hybrid model is required: Specific questions are answered better by choosing the answer from a fixed vocabulary or by extracting it from a predicted bounding box in the plot, while other questions are answered with a table question-answering engine which is fed with a structured table extracted by visual element detection. For the latter, we propose the VOES pipeline and combine it with SAN-VQA to form a hybrid model SAN-VOES. On the DVQA dataset, SAN-VOES model has an accuracy of 58%, significantly improving on highest reported accuracy of 46%. On the PlotQA dataset, SAN-VOES has an accuracy of 54%, which is the highest amongst all the models we trained. Analysis of each module in the VOES pipeline reveals that further improvement in accuracy requires more accurate visual element detection.