 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Interpretation over Plots
Paper and Code
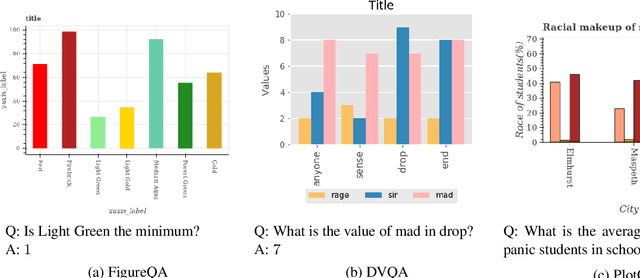
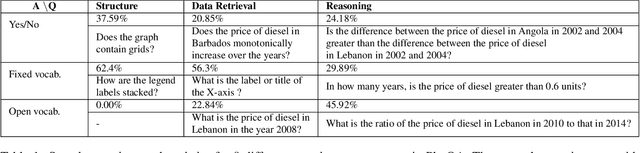

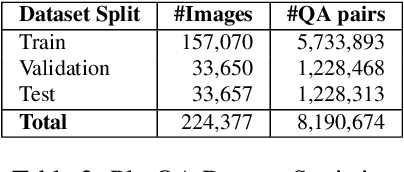
Reasoning over plots by question answering (QA) is a challenging machine learning task at the intersection of vision, language processing, and reasoning. Existing synthetic datasets (FigureQA, DVQA) do not model variability in data labels, real-valued data, or complex reasoning questions. Consequently, proposed models for these datasets do not fully address the challenge of reasoning over plots. We propose PlotQA with 8.1 million question-answer pairs over 220,000 plots with data from real-world sources and questions based on crowd-sourced question templates. 26% of the questions in PlotQA have answers that are not in a fixed vocabulary, requiring reasoning capabilities. Analysis of existing models on PlotQA reveals that a hybrid model is required: Specific questions are answered better by choosing the answer from a fixed vocabulary or by extracting it from a predicted bounding box in the plot, while other questions are answered with a table question-answering engine which is fed with a structured table extracted by visual element detection. For the latter, we propose the VOES pipeline and combine it with SAN-VQA to form a hybrid model SAN-VOES. On the DVQA dataset, SAN-VOES model has an accuracy of 58%, significantly improving on highest reported accuracy of 46%. On the PlotQA dataset, SAN-VOES has an accuracy of 54%, which is the highest amongst all the models we trained. Analysis of each module in the VOES pipeline reveals that further improvement in accuracy requires more accurate visual element detection.