 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Precision PointPillars for Efficient 3D Object Detection with TensorRT
Jan 19, 2026LIDAR 3D object detection is one of the important tasks for autonomous vehicles. Ensuring that this task operates in real-time is crucial. Toward this, model quantization can be used to accelerate the runtime. However, directly applying model quantization often leads to performance degradation due to LIDAR's wide numerical distributions and extreme outliers. To address the wide numerical distribution, we proposed a mixed precision framework designed for PointPillars. Our framework first searches for sensitive layers with post-training quantization (PTQ) by quantizing one layer at a time to 8-bit integer (INT8) and evaluating each model for average precision (AP). The top-k most sensitive layers are assigned as floating point (FP). Combinations of these layers are greedily searched to produce candidate mixed precision models, which are finalized with either PTQ or quantization-aware training (QAT). Furthermore, to handle outliers, we observe that using a very small number of calibration data reduces the likelihood of encountering outliers, thereby improving PTQ performance. Our methods provides mixed precision models without training in the PTQ pipeline, while our QAT pipeline achieves the performance competitive to FP models. With TensorRT deployment, our models offer less latency and sizes by up to 2.35 and 2.26 times, respectively.
Harden Deep Neural Networks Against Fault Injections Through Weight Scaling
Nov 28, 2024Deep neural networks (DNNs) have enabled smart applications on hardware devices. However, these hardware devices are vulnerable to unintended faults caused by aging, temperature variance, and write errors. These faults can cause bit-flips in DNN weights and significantly degrade the performance of DNNs. Thus, protection against these faults is crucial for the deployment of DNNs in critical applications. Previous works have proposed error correction codes based methods, however these methods often require high overheads in both memory and computation. In this paper, we propose a simple yet effective method to harden DNN weights by multiplying weights by constants before storing them to fault-prone medium. When used, these weights are divided back by the same constants to restore the original scale. Our method is based on the observation that errors from bit-flips have properties similar to additive noise, therefore by dividing by constants can reduce the absolute error from bit-flips. To demonstrate our method, we conduct experiments across four ImageNet 2012 pre-trained models along with three different data types: 32-bit floating point, 16-bit floating point, and 8-bit fixed point. This method demonstrates that by only multiplying weights with constants, Top-1 Accuracy of 8-bit fixed point ResNet50 is improved by 54.418 at bit-error rate of 0.0001.
Enhancing Neural Network Robustness Against Fault Injection Through Non-linear Weight Transformations
Nov 28, 2024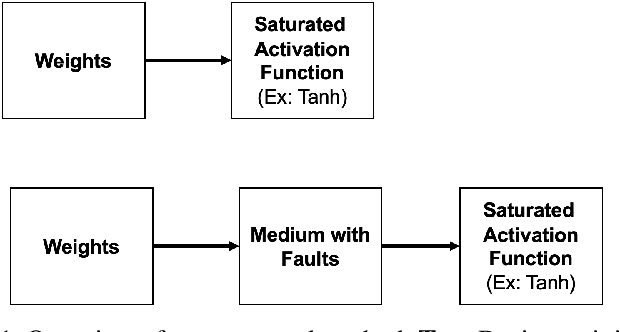
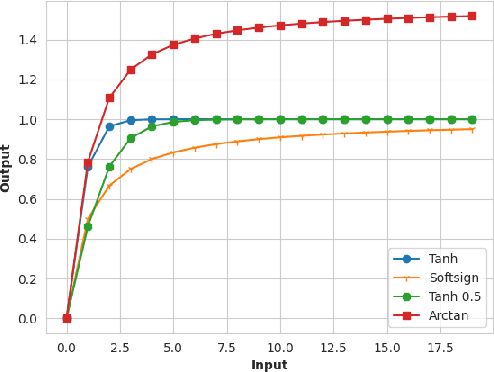
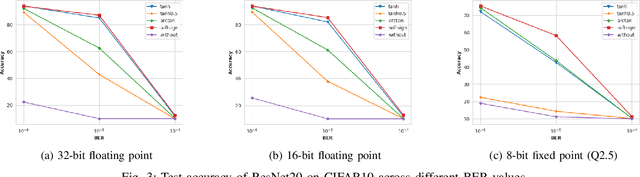
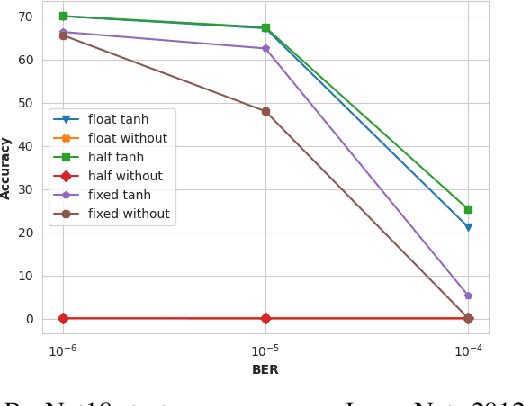
Deploying deep neural networks (DNNs) in real-world environments poses challenges due to faults that can manifest in physical hardware from radiation, aging, and temperature fluctuations. To address this, previous works have focused on protecting DNNs via activation range restriction using clipped ReLU and finding the optimal clipping threshold. However, this work instead focuses on constraining DNN weights by applying saturated activation functions (SAFs): Tanh, Arctan, and others. SAFs prevent faults from causing DNN weights to become excessively large, which can lead to model failure. These methods not only enhance the robustness of DNNs against fault injections but also improve DNN performance by a small margin. Before deployment, DNNs are trained with weights constrained by SAFs. During deployment, the weights without applied SAF are written to mediums with faults. When read, weights with faults are applied with SAFs and are used for inference. We demonstrate our proposed method across three datasets (CIFAR10, CIFAR100, ImageNet 2012) and across three datatypes (32-bit floating point (FP32), 16-bit floating point, and 8-bit fixed point). We show that our method enables FP32 ResNet18 with ImageNet 2012 to operate at a bit-error rate of 0.00001 with minor accuracy loss, while without the proposed method, the FP32 DNN only produces random guesses. Furthermore, to accelerate the training process, we demonstrate that an ImageNet 2012 pre-trained ResNet18 can be adapted to SAF by training for a few epochs with a slight improvement in Top-1 accuracy while still ensuring robustness against fault injection.
Network with Sub-Networks
Aug 02, 2019

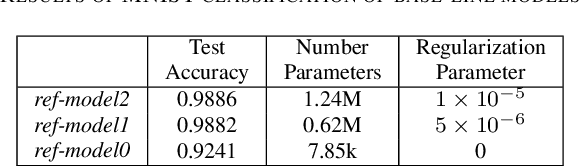

We introduce network with sub-network, a neural network which their weight layer could be removed into sub-neural networks on demand during inference. This method provides selectivity in the number of weight layer. To develop the parameters which could be used in both base and sub-neural networks models, firstly, the weights and biases are copied from sub-models to base-model. Each model is forwarded separately. Gradients from both networks are averaged and, used to update both networks. From the empirical experiment, our base-model achieves the test-accuracy that is comparable to the regularly trained models, while it maintains the ability to remove the weight layers.