 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Neural Network Robustness Against Fault Injection Through Non-linear Weight Transformations
Paper and Code
Nov 28, 2024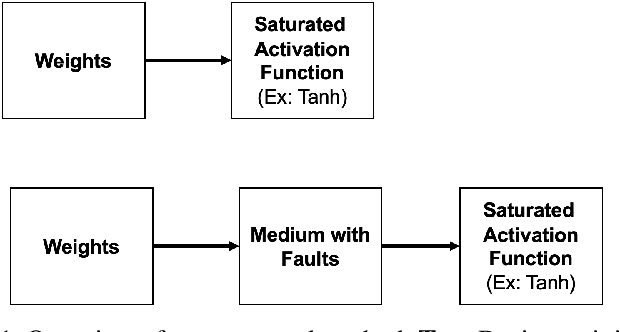
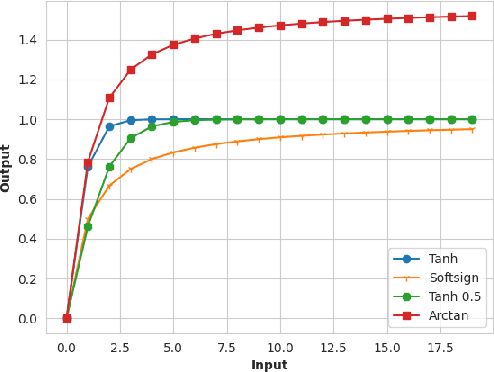
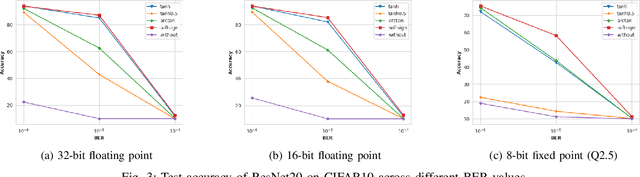
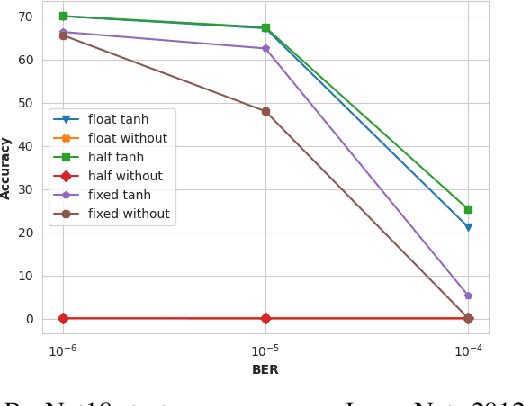
Deploying deep neural networks (DNNs) in real-world environments poses challenges due to faults that can manifest in physical hardware from radiation, aging, and temperature fluctuations. To address this, previous works have focused on protecting DNNs via activation range restriction using clipped ReLU and finding the optimal clipping threshold. However, this work instead focuses on constraining DNN weights by applying saturated activation functions (SAFs): Tanh, Arctan, and others. SAFs prevent faults from causing DNN weights to become excessively large, which can lead to model failure. These methods not only enhance the robustness of DNNs against fault injections but also improve DNN performance by a small margin. Before deployment, DNNs are trained with weights constrained by SAFs. During deployment, the weights without applied SAF are written to mediums with faults. When read, weights with faults are applied with SAFs and are used for inference. We demonstrate our proposed method across three datasets (CIFAR10, CIFAR100, ImageNet 2012) and across three datatypes (32-bit floating point (FP32), 16-bit floating point, and 8-bit fixed point). We show that our method enables FP32 ResNet18 with ImageNet 2012 to operate at a bit-error rate of 0.00001 with minor accuracy loss, while without the proposed method, the FP32 DNN only produces random guesses. Furthermore, to accelerate the training process, we demonstrate that an ImageNet 2012 pre-trained ResNet18 can be adapted to SAF by training for a few epochs with a slight improvement in Top-1 accuracy while still ensuring robustness against fault injection.