 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDyMem: Efficient Federated Learning with Dynamic Memory and Memory-Reduce for Unsupervised Image Anomaly Detection
Feb 28, 2025



Unsupervised image anomaly detection (UAD) has become a critical process in industrial and medical applications, but it faces growing challenges due to increasing concerns over data privacy. The limited class diversity inherent to one-class classification tasks, combined with distribution biases caused by variations in products across and within clients, poses significant challenges for preserving data privacy with federated UAD. Thus, this article proposes an efficient federated learning method with dynamic memory and memory-reduce for unsupervised image anomaly detection, called FedDyMem. Considering all client data belongs to a single class (i.e., normal sample) in UAD and the distribution of intra-class features demonstrates significant skewness, FedDyMem facilitates knowledge sharing between the client and server through the client's dynamic memory bank instead of model parameters. In the local clients, a memory generator and a metric loss are employed to improve the consistency of the feature distribution for normal samples, leveraging the local model to update the memory bank dynamically. For efficient communication, a memory-reduce method based on weighted averages is proposed to significantly decrease the scale of memory banks. On the server, global memory is constructed and distributed to individual clients through k-means aggregation. Experiments conducted on six industrial and medical datasets, comprising a mixture of six products or health screening types derived from eleven public datasets, demonstrate the effectiveness of FedDyMem.
Texture-AD: An Anomaly Detection Dataset and Benchmark for Real Algorithm Development
Sep 10, 2024



Anomaly detection is a crucial process in industrial manufacturing and has made significant advancements recently. However, there is a large variance between the data used in the development and the data collected by the production environment. Therefore, we present the Texture-AD benchmark based on representative texture-based anomaly detection to evaluate the effectiveness of unsupervised anomaly detection algorithms in real-world applications. This dataset includes images of 15 different cloth, 14 semiconductor wafers and 10 metal plates acquired under different optical schemes. In addition, it includes more than 10 different types of defects produced during real manufacturing processes, such as scratches, wrinkles, color variations and point defects, which are often more difficult to detect than existing datasets. All anomalous areas are provided with pixel-level annotations to facilitate comprehensive evaluation using anomaly detection models. Specifically, to adapt to diverse products in automated pipelines, we present a new evaluation method and results of baseline algorithms. The experimental results show that Texture-AD is a difficult challenge for state-of-the-art algorithms. To our knowledge, Texture-AD is the first dataset to be devoted to evaluating industrial defect detection algorithms in the real world. The dataset is available at https://XXX.
Adapted-MoE: Mixture of Experts with Test-Time Adaption for Anomaly Detection
Sep 09, 2024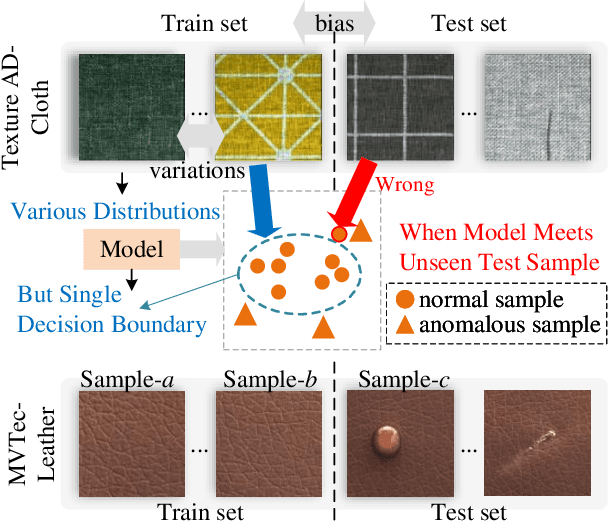
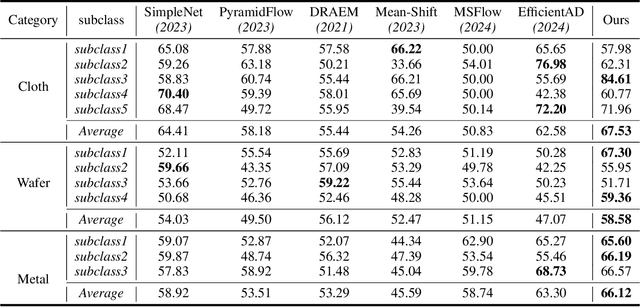
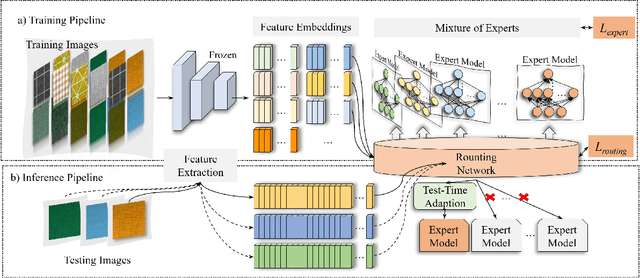
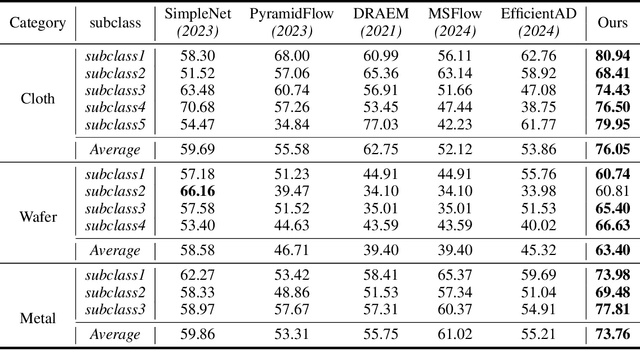
Most unsupervised anomaly detection methods based on representations of normal samples to distinguish anomalies have recently made remarkable progress. However, existing methods only learn a single decision boundary for distinguishing the samples within the training dataset, neglecting the variation in feature distribution for normal samples even in the same category in the real world. Furthermore, it was not considered that a distribution bias still exists between the test set and the train set. Therefore, we propose an Adapted-MoE which contains a routing network and a series of expert models to handle multiple distributions of same-category samples by divide and conquer. Specifically, we propose a routing network based on representation learning to route same-category samples into the subclasses feature space. Then, a series of expert models are utilized to learn the representation of various normal samples and construct several independent decision boundaries. We propose the test-time adaption to eliminate the bias between the unseen test sample representation and the feature distribution learned by the expert model. Our experiments are conducted on a dataset that provides multiple subclasses from three categories, namely Texture AD benchmark. The Adapted-MoE significantly improves the performance of the baseline model, achieving 2.18%-7.20% and 1.57%-16.30% increase in I-AUROC and P-AUROC, which outperforms the current state-of-the-art methods. Our code is available at https://github.com/.