 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Dense Passage Retrieval using Transformers
Aug 15, 2022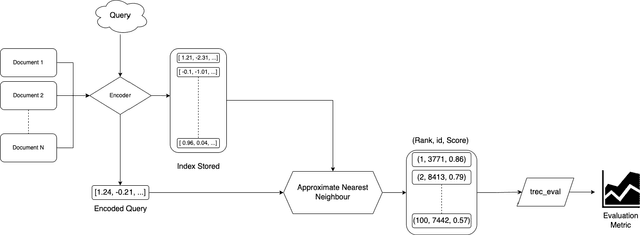

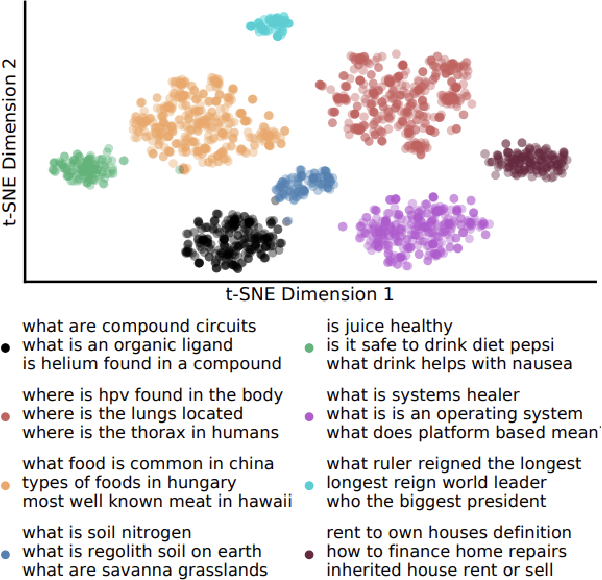
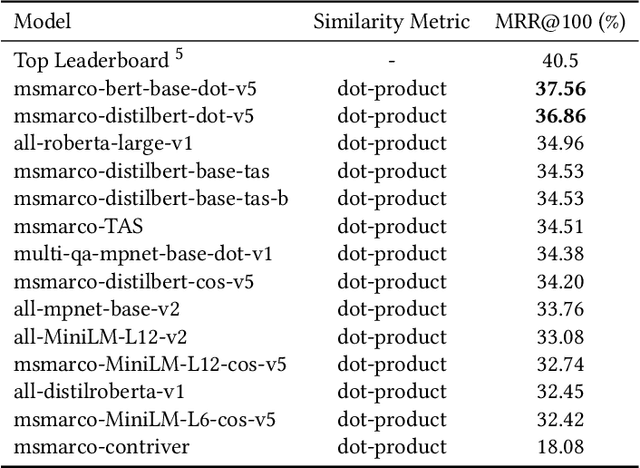
Although representational retrieval models based on Transformers have been able to make major advances in the past few years, and despite the widely accepted conventions and best-practices for testing such models, a $\textit{standardized}$ evaluation framework for testing them has not been developed. In this work, we formalize the best practices and conventions followed by researchers in the literature, paving the path for more standardized evaluations - and therefore more fair comparisons between the models. Our framework (1) embeds the documents and queries; (2) for each query-document pair, computes the relevance score based on the dot product of the document and query embedding; (3) uses the $\texttt{dev}$ set of the MSMARCO dataset to evaluate the models; (4) uses the $\texttt{trec_eval}$ script to calculate MRR@100, which is the primary metric used to evaluate the models. Most importantly, we showcase the use of this framework by experimenting on some of the most well-known dense retrieval models.
Continuous Active Learning Using Pretrained Transformers
Aug 15, 2022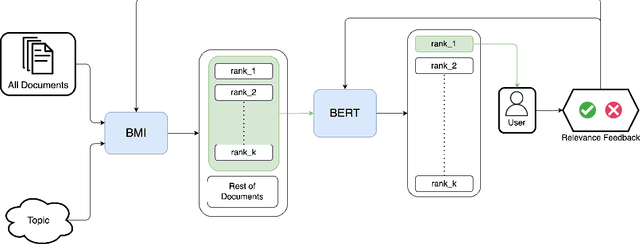
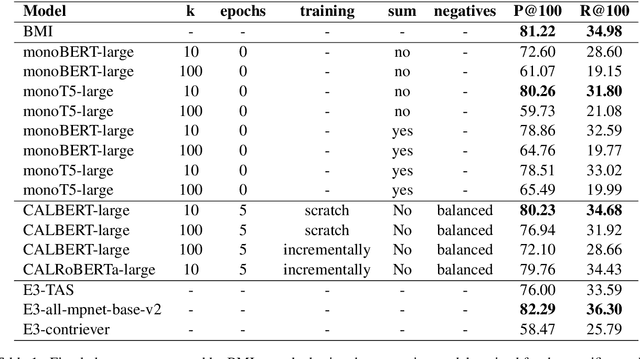
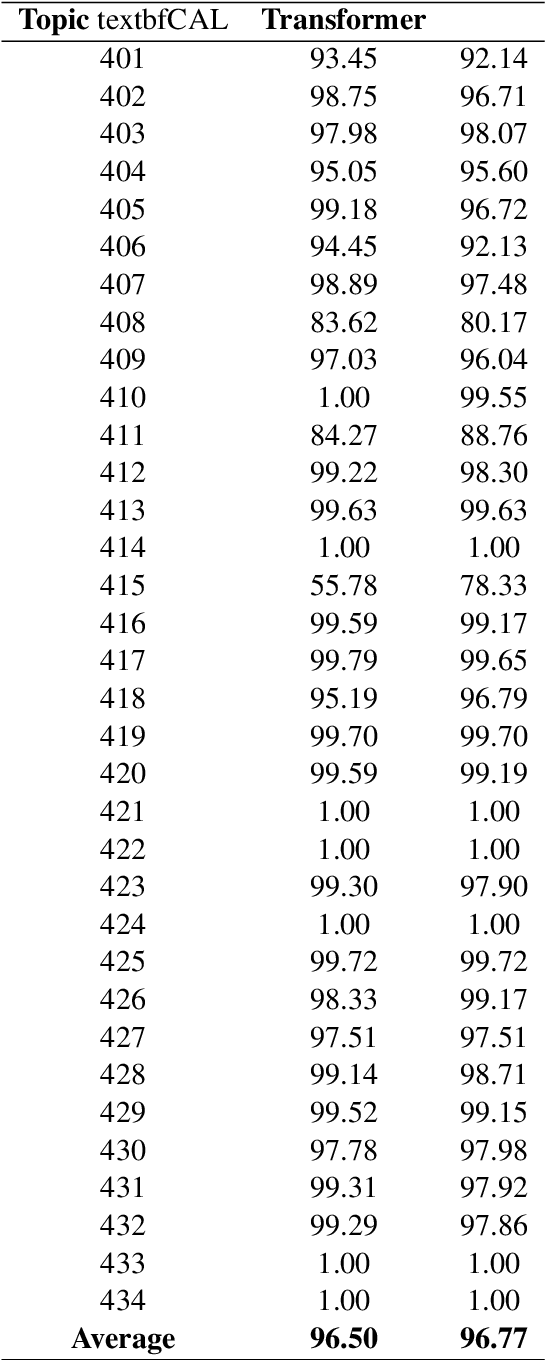
Pre-trained and fine-tuned transformer models like BERT and T5 have improved the state of the art in ad-hoc retrieval and question-answering, but not as yet in high-recall information retrieval, where the objective is to retrieve substantially all relevant documents. We investigate whether the use of transformer-based models for reranking and/or featurization can improve the Baseline Model Implementation of the TREC Total Recall Track, which represents the current state of the art for high-recall information retrieval. We also introduce CALBERT, a model that can be used to continuously fine-tune a BERT-based model based on relevance feedback.
MeetSum: Transforming Meeting Transcript Summarization using Transformers!
Aug 13, 2021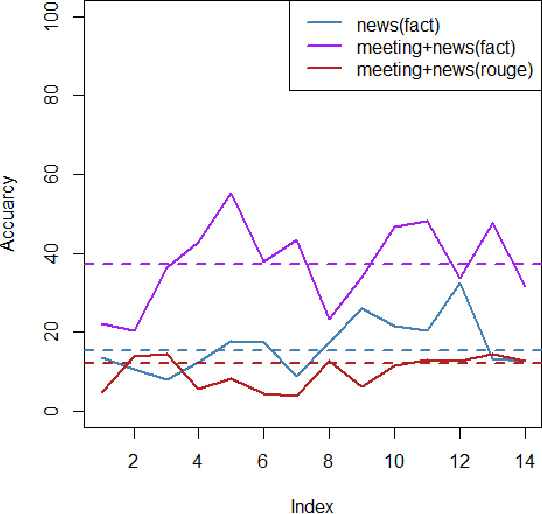



Creating abstractive summaries from meeting transcripts has proven to be challenging due to the limited amount of labeled data available for training neural network models. Moreover, Transformer-based architectures have proven to beat state-of-the-art models in summarizing news data. In this paper, we utilize a Transformer-based Pointer Generator Network to generate abstract summaries for meeting transcripts. This model uses 2 LSTMs as an encoder and a decoder, a Pointer network which copies words from the inputted text, and a Generator network to produce out-of-vocabulary words (hence making the summary abstractive). Moreover, a coverage mechanism is used to avoid repetition of words in the generated summary. First, we show that training the model on a news summary dataset and using zero-shot learning to test it on the meeting dataset proves to produce better results than training it on the AMI meeting dataset. Second, we show that training this model first on out-of-domain data, such as the CNN-Dailymail dataset, followed by a fine-tuning stage on the AMI meeting dataset is able to improve the performance of the model significantly. We test our model on a testing set from the AMI dataset and report the ROUGE-2 score of the generated summary to compare with previous literature. We also report the Factual score of our summaries since it is a better benchmark for abstractive summaries since the ROUGE-2 score is limited to measuring word-overlaps. We show that our improved model is able to improve on previous models by at least 5 ROUGE-2 scores, which is a substantial improvement. Also, a qualitative analysis of the summaries generated by our model shows that these summaries and human-readable and indeed capture most of the important information from the transcripts.