Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Active Learning Using Pretrained Transformers
Paper and Code
Aug 15, 2022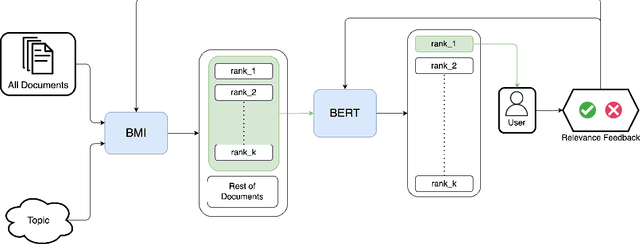
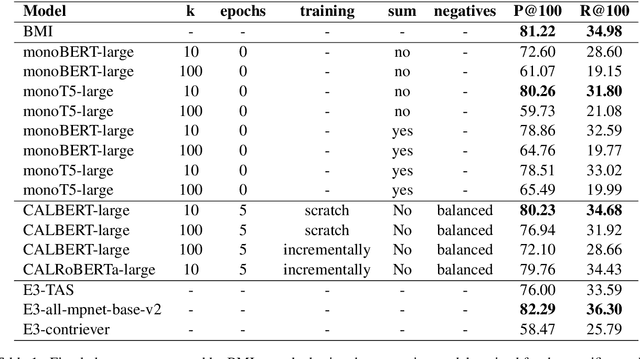
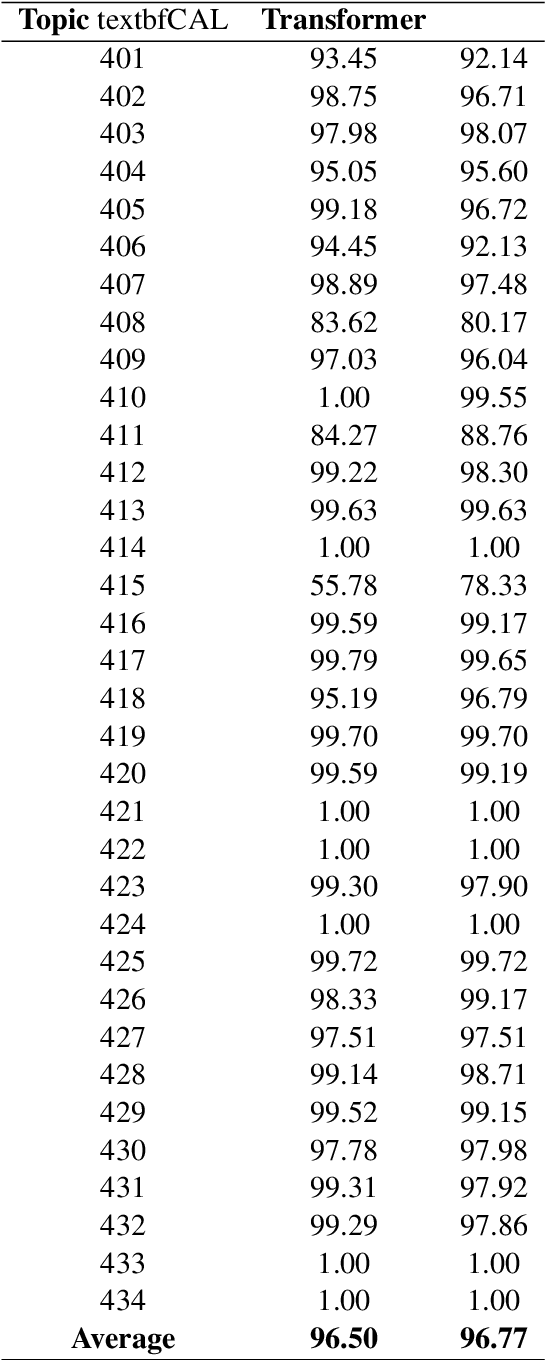
Pre-trained and fine-tuned transformer models like BERT and T5 have improved the state of the art in ad-hoc retrieval and question-answering, but not as yet in high-recall information retrieval, where the objective is to retrieve substantially all relevant documents. We investigate whether the use of transformer-based models for reranking and/or featurization can improve the Baseline Model Implementation of the TREC Total Recall Track, which represents the current state of the art for high-recall information retrieval. We also introduce CALBERT, a model that can be used to continuously fine-tune a BERT-based model based on relevance feedback.
View paper on