 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Dense Passage Retrieval using Transformers
Paper and Code
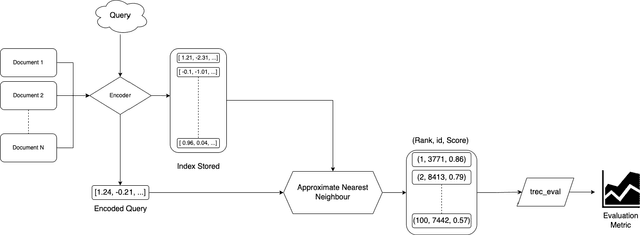

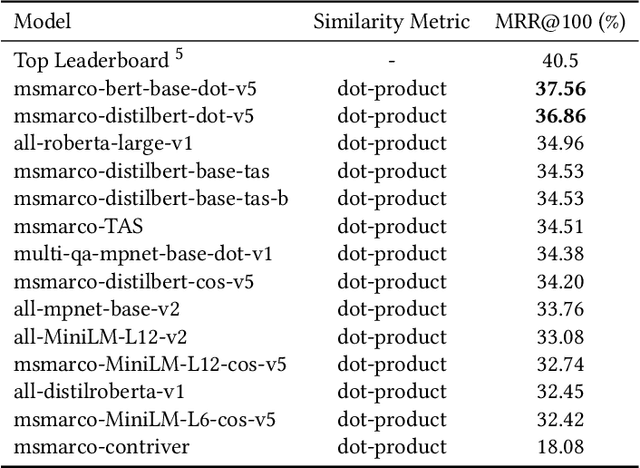
Although representational retrieval models based on Transformers have been able to make major advances in the past few years, and despite the widely accepted conventions and best-practices for testing such models, a $\textit{standardized}$ evaluation framework for testing them has not been developed. In this work, we formalize the best practices and conventions followed by researchers in the literature, paving the path for more standardized evaluations - and therefore more fair comparisons between the models. Our framework (1) embeds the documents and queries; (2) for each query-document pair, computes the relevance score based on the dot product of the document and query embedding; (3) uses the $\texttt{dev}$ set of the MSMARCO dataset to evaluate the models; (4) uses the $\texttt{trec_eval}$ script to calculate MRR@100, which is the primary metric used to evaluate the models. Most importantly, we showcase the use of this framework by experimenting on some of the most well-known dense retrieval models.