 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-VITS: Data-Efficient Noise-Robust Zero-Shot Voice Cloning via Multi-Tasking with Self-Supervised Speaker Verification Loss
Nov 17, 2023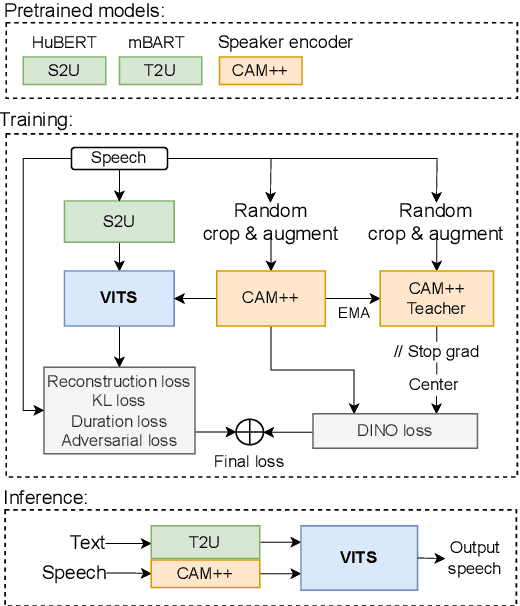



Recent progress in self-supervised representation learning has opened up new opportunities for training from unlabeled data and has been a growing trend in voice conversion. However, unsupervised training of voice cloning seems to remain a challenging task. In this paper we propose a semi-supervised zero-shot voice cloning approach that works by adapting a HuBERT-based voice conversion system to the voice cloning task and shows the robustness of such a system to noises both in training data (we add noises resulting in up to 0db signal-to-noise-ratio to 35% of training data with no significant degradation of evaluation metrics) and in the target speaker reference audio at inference. Moreover, such a method does not require any type of denoising or noise-labeling of training data. Finally, we introduce a novel multi-tasking approach by incorporating self-supervised DINO loss into joint training of a CAM++ based speaker verification system and a unit-based VITS cloning system. We show that it significantly improves the quality of generated audio over baselines, especially for noisy target speaker references.