 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonverbalTTS: A Public English Corpus of Text-Aligned Nonverbal Vocalizations with Emotion Annotations for Text-to-Speech
Jul 17, 2025Current expressive speech synthesis models are constrained by the limited availability of open-source datasets containing diverse nonverbal vocalizations (NVs). In this work, we introduce NonverbalTTS (NVTTS), a 17-hour open-access dataset annotated with 10 types of NVs (e.g., laughter, coughs) and 8 emotional categories. The dataset is derived from popular sources, VoxCeleb and Expresso, using automated detection followed by human validation. We propose a comprehensive pipeline that integrates automatic speech recognition (ASR), NV tagging, emotion classification, and a fusion algorithm to merge transcriptions from multiple annotators. Fine-tuning open-source text-to-speech (TTS) models on the NVTTS dataset achieves parity with closed-source systems such as CosyVoice2, as measured by both human evaluation and automatic metrics, including speaker similarity and NV fidelity. By releasing NVTTS and its accompanying annotation guidelines, we address a key bottleneck in expressive TTS research. The dataset is available at https://huggingface.co/datasets/deepvk/NonverbalTTS.
Low-resource Machine Translation for Code-switched Kazakh-Russian Language Pair
Mar 25, 2025Machine translation for low resource language pairs is a challenging task. This task could become extremely difficult once a speaker uses code switching. We propose a method to build a machine translation model for code-switched Kazakh-Russian language pair with no labeled data. Our method is basing on generation of synthetic data. Additionally, we present the first codeswitching Kazakh-Russian parallel corpus and the evaluation results, which include a model achieving 16.48 BLEU almost reaching an existing commercial system and beating it by human evaluation.
DINO-VITS: Data-Efficient Noise-Robust Zero-Shot Voice Cloning via Multi-Tasking with Self-Supervised Speaker Verification Loss
Nov 17, 2023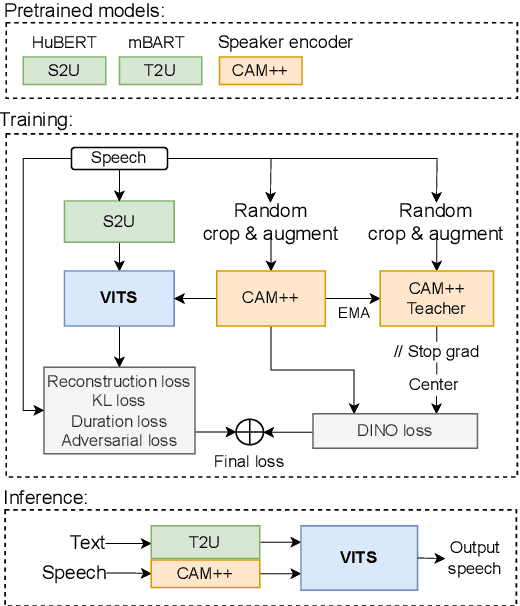



Recent progress in self-supervised representation learning has opened up new opportunities for training from unlabeled data and has been a growing trend in voice conversion. However, unsupervised training of voice cloning seems to remain a challenging task. In this paper we propose a semi-supervised zero-shot voice cloning approach that works by adapting a HuBERT-based voice conversion system to the voice cloning task and shows the robustness of such a system to noises both in training data (we add noises resulting in up to 0db signal-to-noise-ratio to 35% of training data with no significant degradation of evaluation metrics) and in the target speaker reference audio at inference. Moreover, such a method does not require any type of denoising or noise-labeling of training data. Finally, we introduce a novel multi-tasking approach by incorporating self-supervised DINO loss into joint training of a CAM++ based speaker verification system and a unit-based VITS cloning system. We show that it significantly improves the quality of generated audio over baselines, especially for noisy target speaker references.