 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake detection in videos with multiple faces using geometric-fakeness features
Oct 10, 2024
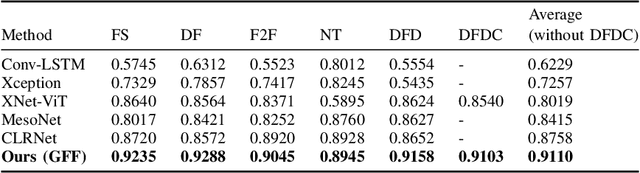

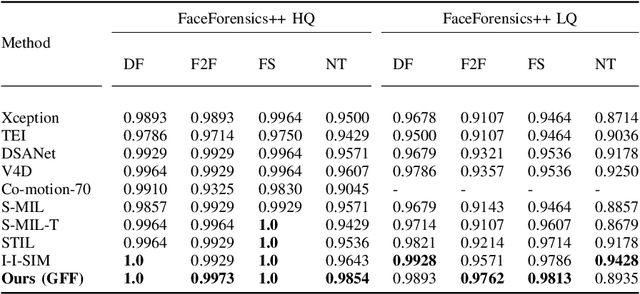
Due to the development of facial manipulation techniques in recent years deepfake detection in video stream became an important problem for face biometrics, brand monitoring or online video conferencing solutions. In case of a biometric authentication, if you replace a real datastream with a deepfake, you can bypass a liveness detection system. Using a deepfake in a video conference, you can penetrate into a private meeting. Deepfakes of victims or public figures can also be used by fraudsters for blackmailing, extorsion and financial fraud. Therefore, the task of detecting deepfakes is relevant to ensuring privacy and security. In existing approaches to a deepfake detection their performance deteriorates when multiple faces are present in a video simultaneously or when there are other objects erroneously classified as faces. In our research we propose to use geometric-fakeness features (GFF) that characterize a dynamic degree of a face presence in a video and its per-frame deepfake scores. To analyze temporal inconsistencies in GFFs between the frames we train a complex deep learning model that outputs a final deepfake prediction. We employ our approach to analyze videos with multiple faces that are simultaneously present in a video. Such videos often occur in practice e.g., in an online video conference. In this case, real faces appearing in a frame together with a deepfake face will significantly affect a deepfake detection and our approach allows to counter this problem. Through extensive experiments we demonstrate that our approach outperforms current state-of-the-art methods on popular benchmark datasets such as FaceForensics++, DFDC, Celeb-DF and WildDeepFake. The proposed approach remains accurate when trained to detect multiple different deepfake generation techniques.
DINO-VITS: Data-Efficient Noise-Robust Zero-Shot Voice Cloning via Multi-Tasking with Self-Supervised Speaker Verification Loss
Nov 17, 2023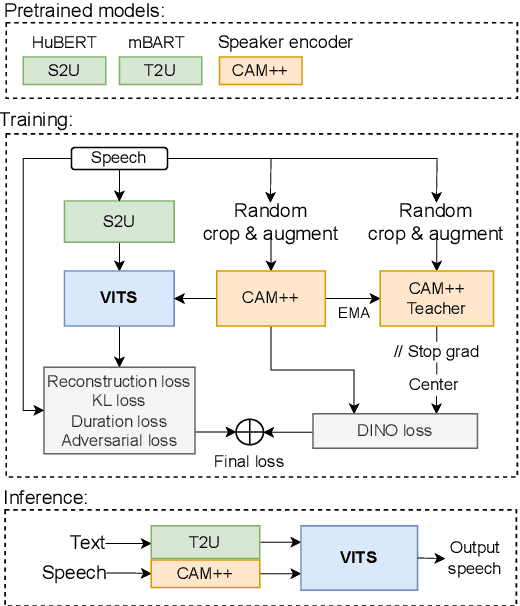



Recent progress in self-supervised representation learning has opened up new opportunities for training from unlabeled data and has been a growing trend in voice conversion. However, unsupervised training of voice cloning seems to remain a challenging task. In this paper we propose a semi-supervised zero-shot voice cloning approach that works by adapting a HuBERT-based voice conversion system to the voice cloning task and shows the robustness of such a system to noises both in training data (we add noises resulting in up to 0db signal-to-noise-ratio to 35% of training data with no significant degradation of evaluation metrics) and in the target speaker reference audio at inference. Moreover, such a method does not require any type of denoising or noise-labeling of training data. Finally, we introduce a novel multi-tasking approach by incorporating self-supervised DINO loss into joint training of a CAM++ based speaker verification system and a unit-based VITS cloning system. We show that it significantly improves the quality of generated audio over baselines, especially for noisy target speaker references.