 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Autonomously Reach Objects with NICO and Grow-When-Required Networks
Oct 17, 2022


The act of reaching for an object is a fundamental yet complex skill for a robotic agent, requiring a high degree of visuomotor control and coordination. In consideration of dynamic environments, a robot capable of autonomously adapting to novel situations is desired. In this paper, a developmental robotics approach is used to autonomously learn visuomotor coordination on the NICO (Neuro-Inspired COmpanion) platform, for the task of object reaching. The robot interacts with its environment and learns associations between motor commands and temporally correlated sensory perceptions based on Hebbian learning. Multiple Grow-When-Required (GWR) networks are used to learn increasingly more complex motoric behaviors, by first learning how to direct the gaze towards a visual stimulus, followed by learning motor control of the arm, and finally learning how to reach for an object using eye-hand coordination. We demonstrate that the model is able to deal with an unforeseen mechanical change in the NICO's body, showing the adaptability of the proposed approach. In evaluations of our approach, we show that the humanoid robot NICO is able to reach objects with a 76% success rate.
Continual Learning from Synthetic Data for a Humanoid Exercise Robot
Feb 19, 2021


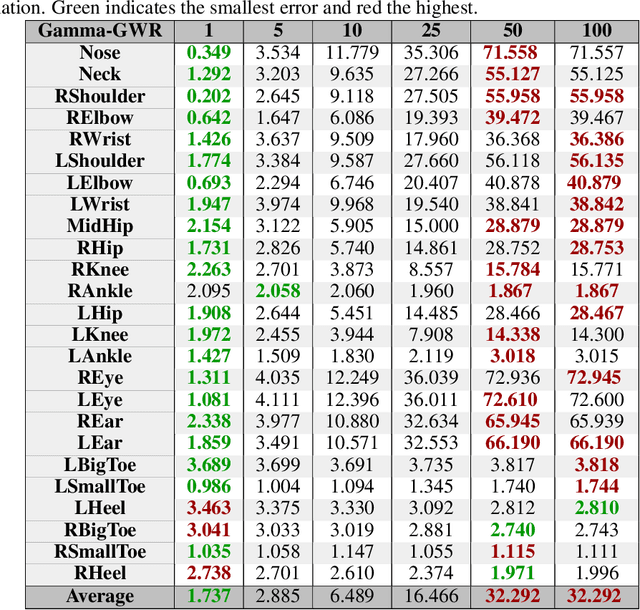
In order to detect and correct physical exercises, a Grow-When-Required Network (GWR) with recurrent connections, episodic memory and a novel subnode mechanism is developed in order to learn spatiotemporal relationships of body movements and poses. Once an exercise is performed, the information of pose and movement per frame is stored in the GWR. For every frame, the current pose and motion pair is compared against a predicted output of the GWR, allowing for feedback not only on the pose but also on the velocity of the motion. In a practical scenario, a physical exercise is performed by an expert like a physiotherapist and then used as a reference for a humanoid robot like Pepper to give feedback on a patient's execution of the same exercise. This approach, however, comes with two challenges. First, the distance from the humanoid robot and the position of the user in the camera's view of the humanoid robot have to be considered by the GWR as well, requiring a robustness against the user's positioning in the field of view of the humanoid robot. Second, since both the pose and motion are dependent on the body measurements of the original performer, the expert's exercise cannot be easily used as a reference. This paper tackles the first challenge by designing an architecture that allows for tolerances in translation and rotations regarding the center of the field of view. For the second challenge, we allow the GWR to grow online on incremental data. For evaluation, we created a novel exercise dataset with virtual avatars called the Virtual-Squat dataset. Overall, we claim that our novel architecture based on the GWR can use a learned exercise reference for different body variations through continual online learning, while preventing catastrophic forgetting, enabling for an engaging long-term human-robot interaction with a humanoid robot.