Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Perception for Ambiguous Objects Classification
Aug 02, 2021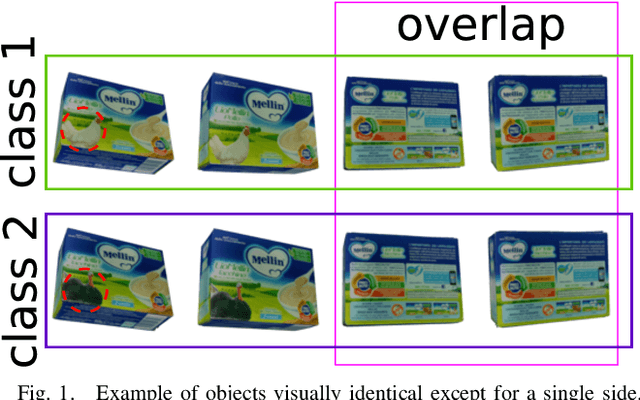
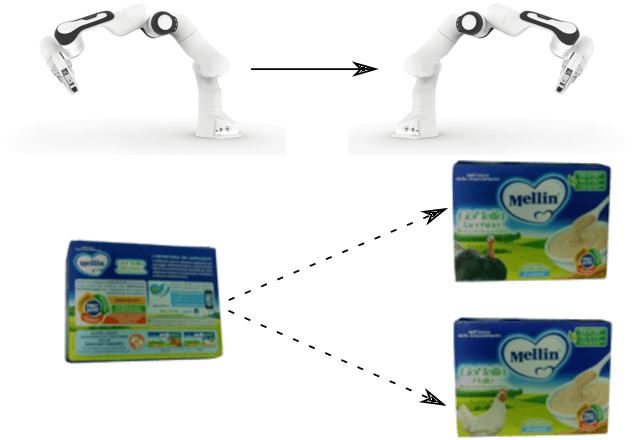
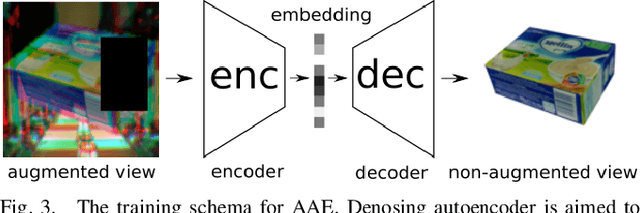
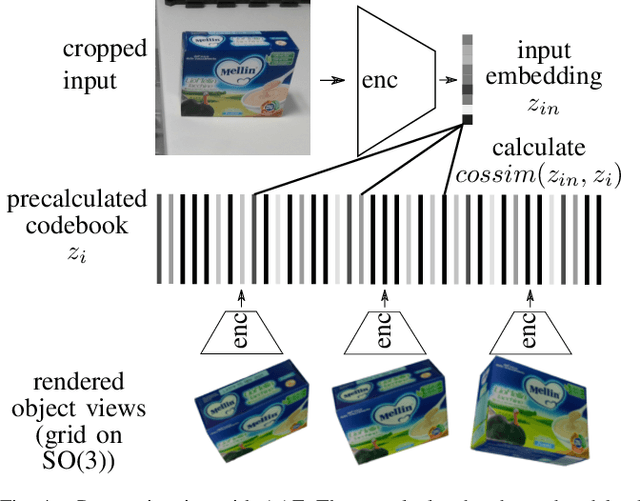
Recent visual pose estimation and tracking solutions provide notable results on popular datasets such as T-LESS and YCB. However, in the real world, we can find ambiguous objects that do not allow exact classification and detection from a single view. In this work, we propose a framework that, given a single view of an object, provides the coordinates of a next viewpoint to discriminate the object against similar ones, if any, and eliminates ambiguities. We also describe a complete pipeline from a real object's scans to the viewpoint selection and classification. We validate our approach with a Franka Emika Panda robot and common household objects featured with ambiguities. We released the source code to reproduce our experiments.
* Accepted version at 2021 IEEE/RSJ International Conference on
Intelligent Robots and Systems (IROS 2021)
Via