 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Hierarchical Gaussian Kernels
Dec 02, 2016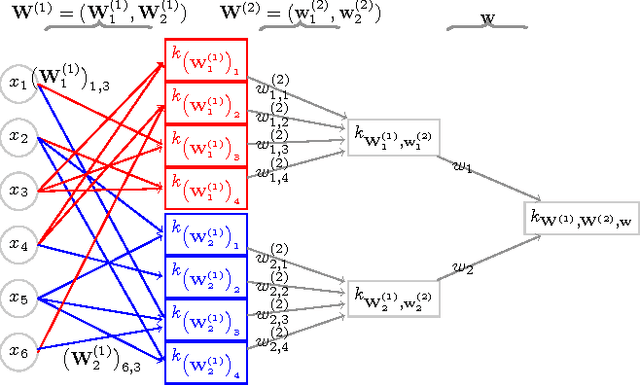
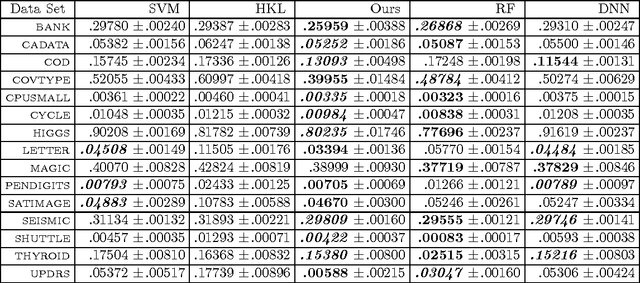
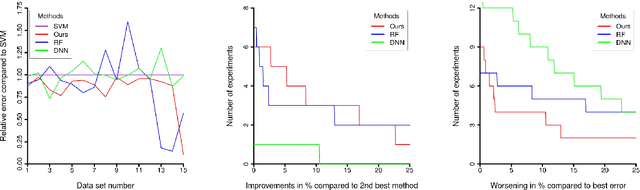
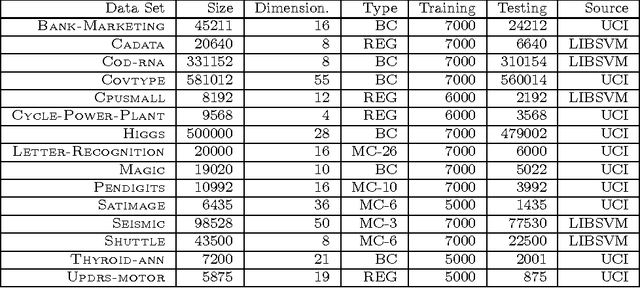
We investigate iterated compositions of weighted sums of Gaussian kernels and provide an interpretation of the construction that shows some similarities with the architectures of deep neural networks. On the theoretical side, we show that these kernels are universal and that SVMs using these kernels are universally consistent. We further describe a parameter optimization method for the kernel parameters and empirically compare this method to SVMs, random forests, a multiple kernel learning approach, and to some deep neural networks.
Towards an Axiomatic Approach to Hierarchical Clustering of Measures
Aug 15, 2015
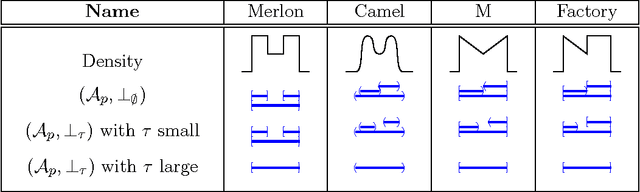
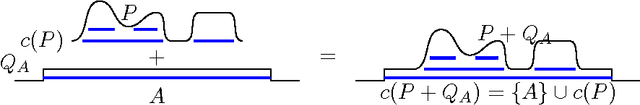

We propose some axioms for hierarchical clustering of probability measures and investigate their ramifications. The basic idea is to let the user stipulate the clusters for some elementary measures. This is done without the need of any notion of metric, similarity or dissimilarity. Our main results then show that for each suitable choice of user-defined clustering on elementary measures we obtain a unique notion of clustering on a large set of distributions satisfying a set of additivity and continuity axioms. We illustrate the developed theory by numerous examples including some with and some without a density.