 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalizable Artificial Intelligence Model for COVID-19 Classification Task Using Chest X-ray Radiographs: Evaluated Over Four Clinical Datasets with 15,097 Patients
Oct 04, 2022
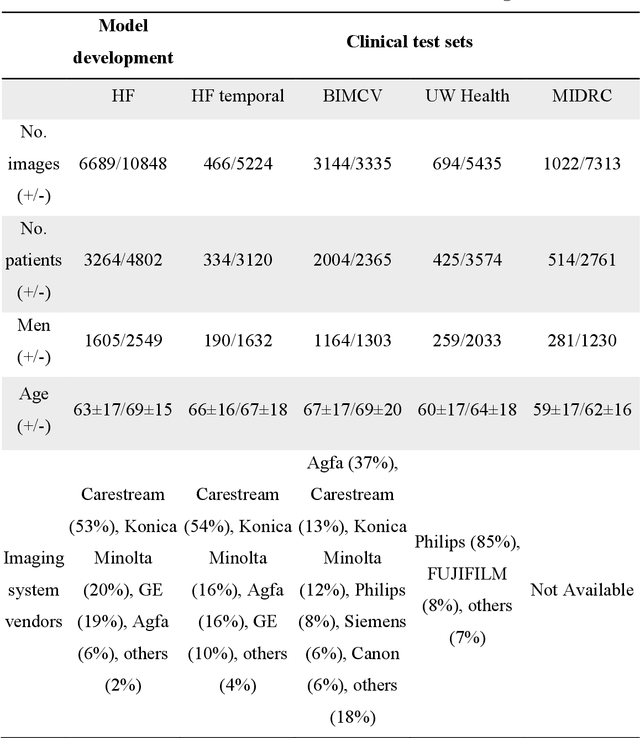
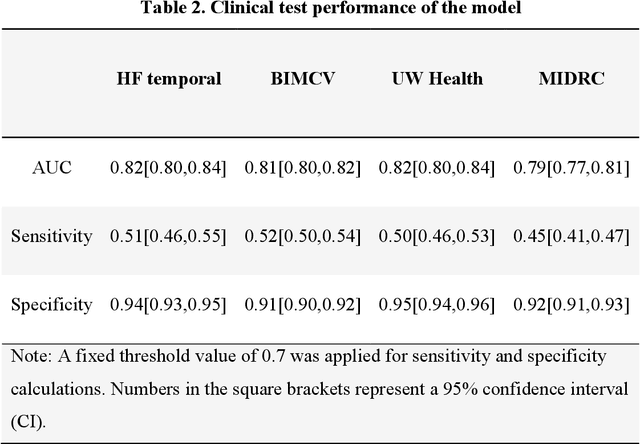
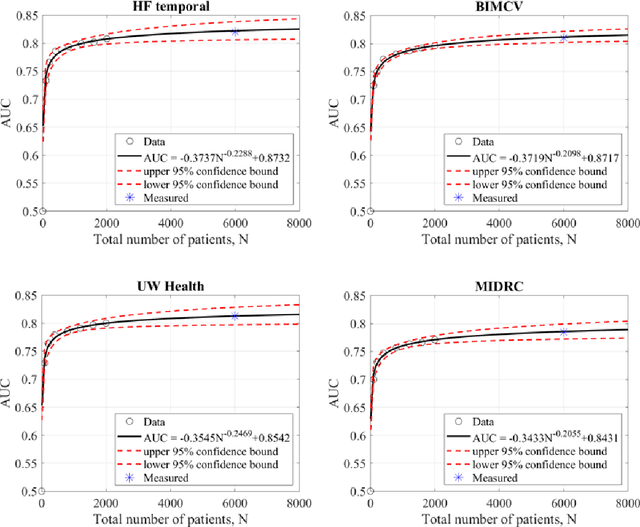
Purpose: To answer the long-standing question of whether a model trained from a single clinical site can be generalized to external sites. Materials and Methods: 17,537 chest x-ray radiographs (CXRs) from 3,264 COVID-19-positive patients and 4,802 COVID-19-negative patients were collected from a single site for AI model development. The generalizability of the trained model was retrospectively evaluated using four different real-world clinical datasets with a total of 26,633 CXRs from 15,097 patients (3,277 COVID-19-positive patients). The area under the receiver operating characteristic curve (AUC) was used to assess diagnostic performance. Results: The AI model trained using a single-source clinical dataset achieved an AUC of 0.82 (95% CI: 0.80, 0.84) when applied to the internal temporal test set. When applied to datasets from two external clinical sites, an AUC of 0.81 (95% CI: 0.80, 0.82) and 0.82 (95% CI: 0.80, 0.84) were achieved. An AUC of 0.79 (95% CI: 0.77, 0.81) was achieved when applied to a multi-institutional COVID-19 dataset collected by the Medical Imaging and Data Resource Center (MIDRC). A power-law dependence, N^(k )(k is empirically found to be -0.21 to -0.25), indicates a relatively weak performance dependence on the training data sizes. Conclusion: COVID-19 classification AI model trained using well-curated data from a single clinical site is generalizable to external clinical sites without a significant drop in performance.