 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectroscopy Approaches for Food Safety Applications: Improving Data Efficiency Using Active Learning and Semi-Supervised Learning
Oct 24, 2021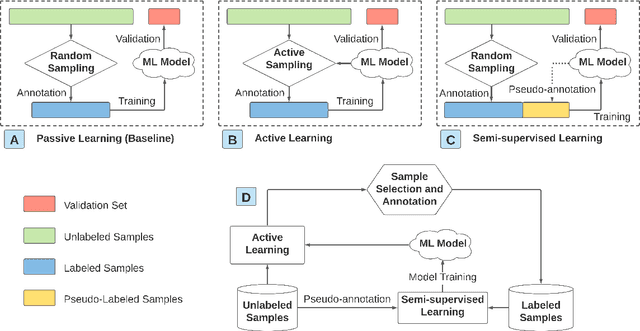

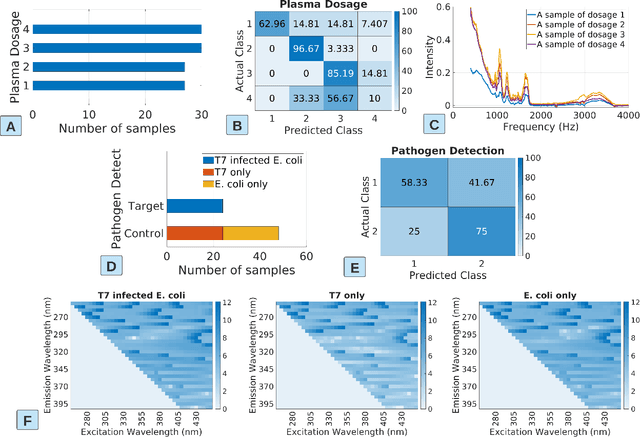
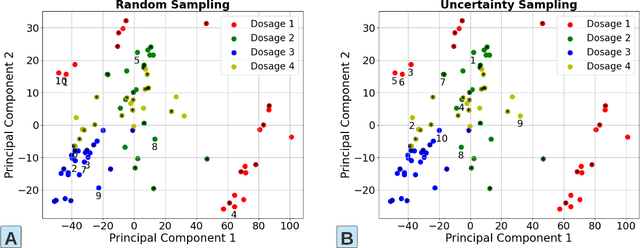
The past decade witnesses a rapid development in the measurement and monitoring technologies for food science. Among these technologies, spectroscopy has been widely used for the analysis of food quality, safety, and nutritional properties. Due to the complexity of food systems and the lack of comprehensive predictive models, rapid and simple measurements to predict complex properties in food systems are largely missing. Machine Learning (ML) has shown great potential to improve classification and prediction of these properties. However, the barriers to collect large datasets for ML applications still persists. In this paper, we explore different approaches of data annotation and model training to improve data efficiency for ML applications. Specifically, we leverage Active Learning (AL) and Semi-Supervised Learning (SSL) and investigate four approaches: baseline passive learning, AL, SSL, and a hybrid of AL and SSL. To evaluate these approaches, we collect two spectroscopy datasets: predicting plasma dosage and detecting foodborne pathogen. Our experimental results show that, compared to the de facto passive learning approach, AL and SSL methods reduce the number of labeled samples by 50% and 25% for each ML application, respectively.