 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Sentinels: Assessing AI Performance in Cybersecurity Peer Review
Sep 11, 2023Peer review is the method employed by the scientific community for evaluating research advancements. In the field of cybersecurity, the practice of double-blind peer review is the de-facto standard. This paper touches on the holy grail of peer reviewing and aims to shed light on the performance of AI in reviewing for academic security conferences. Specifically, we investigate the predictability of reviewing outcomes by comparing the results obtained from human reviewers and machine-learning models. To facilitate our study, we construct a comprehensive dataset by collecting thousands of papers from renowned computer science conferences and the arXiv preprint website. Based on the collected data, we evaluate the prediction capabilities of ChatGPT and a two-stage classification approach based on the Doc2Vec model with various classifiers. Our experimental evaluation of review outcome prediction using the Doc2Vec-based approach performs significantly better than the ChatGPT and achieves an accuracy of over 90%. While analyzing the experimental results, we identify the potential advantages and limitations of the tested ML models. We explore areas within the paper-reviewing process that can benefit from automated support approaches, while also recognizing the irreplaceable role of human intellect in certain aspects that cannot be matched by state-of-the-art AI techniques.
GAKP: GRU Association and Kalman Prediction for Multiple Object Tracking
Dec 28, 2020

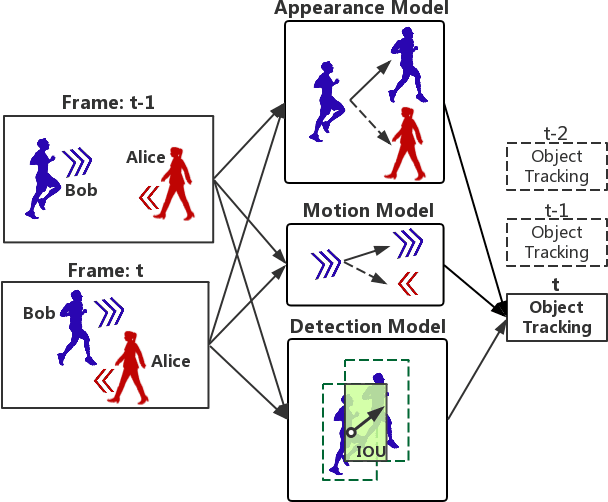

Multiple Object Tracking (MOT) has been a useful yet challenging task in many real-world applications such as video surveillance, intelligent retail, and smart city. The challenge is how to model long-term temporal dependencies in an efficient manner. Some recent works employ Recurrent Neural Networks (RNN) to obtain good performance, which, however, requires a large amount of training data. In this paper, we proposed a novel tracking method that integrates the auto-tuning Kalman method for prediction and the Gated Recurrent Unit (GRU) and achieves a near-optimum with a small amount of training data. Experimental results show that our new algorithm can achieve competitive performance on the challenging MOT benchmark, and faster and more robust than the state-of-the-art RNN-based online MOT algorithms.
Progressive Learning Algorithm for Efficient Person Re-Identification
Dec 16, 2019
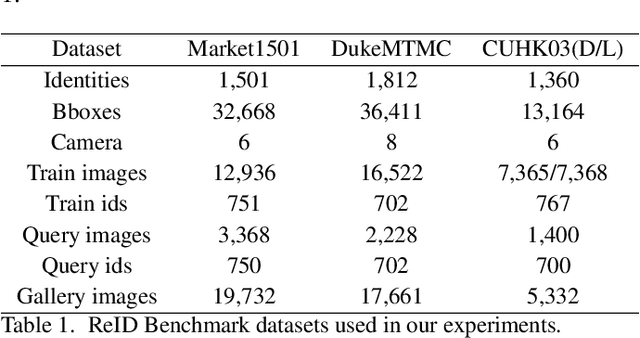
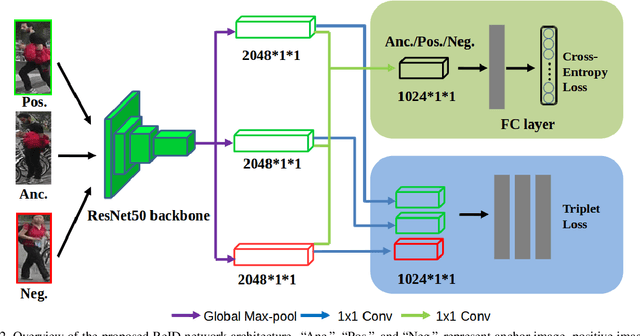
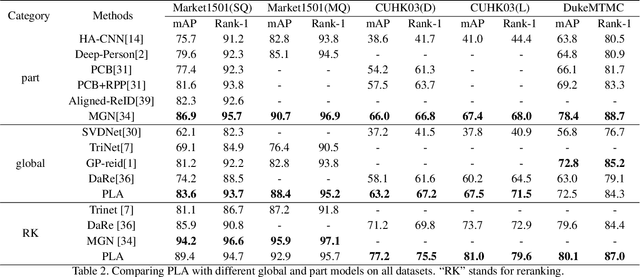
This paper studies the problem of Person Re-Identification (ReID)for large-scale applications. Recent research efforts have been devoted to building complicated part models, which introduce considerably high computational cost and memory consumption, inhibiting its practicability in large-scale applications. This paper aims to develop a novel learning strategy to find efficient feature embeddings while maintaining the balance of accuracy and model complexity. More specifically, we find by enhancing the classical triplet loss together with cross-entropy loss, our method can explore the hard examples and build a discriminant feature embedding yet compact enough for large-scale applications. Our method is carried out progressively using Bayesian optimization, and we call it the Progressive Learning Algorithm (PLA). Extensive experiments on three large-scale datasets show that our PLA is comparable or better than the-state-of-the-arts. Especially, on the challenging Market-1501 dataset, we achieve Rank-1=94.7\%/mAP=89.4\% while saving at least 30\% parameters than strong part models.