 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Inequality of LLM Fact-Checking over Geographic Regions with Agent and Retrieval models
Mar 28, 2025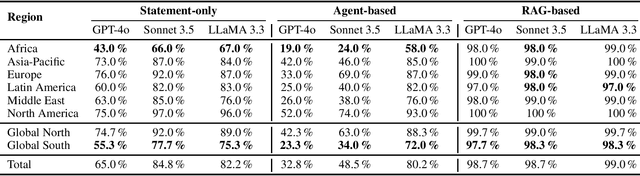
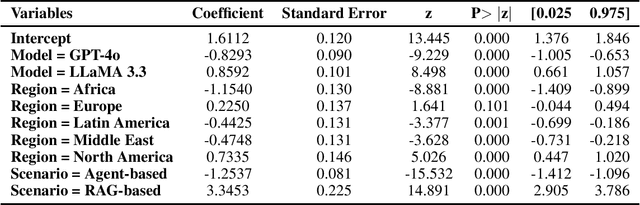
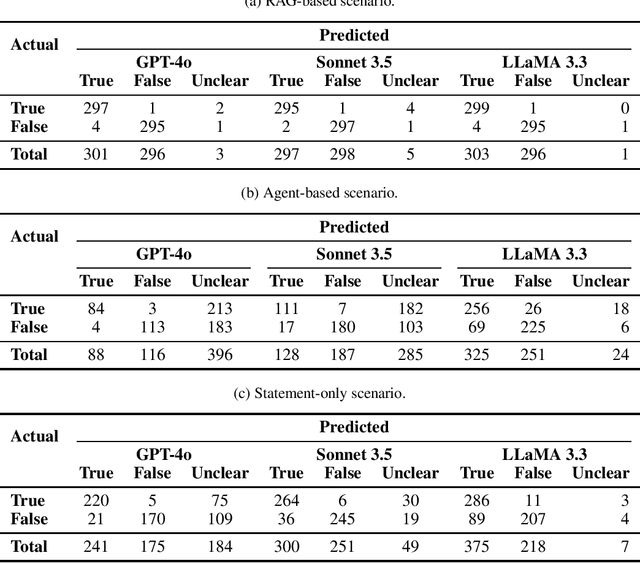

Fact-checking is a potentially useful application of Large Language Models (LLMs) to combat the growing dissemination of disinformation. However, the performance of LLMs varies across geographic regions. In this paper, we evaluate the factual accuracy of open and private models across a diverse set of regions and scenarios. Using a dataset containing 600 fact-checked statements balanced across six global regions we examine three experimental setups of fact-checking a statement: (1) when just the statement is available, (2) when an LLM-based agent with Wikipedia access is utilized, and (3) as a best case scenario when a Retrieval-Augmented Generation (RAG) system provided with the official fact check is employed. Our findings reveal that regardless of the scenario and LLM used, including GPT-4, Claude Sonnet, and LLaMA, statements from the Global North perform substantially better than those from the Global South. Furthermore, this gap is broadened for the more realistic case of a Wikipedia agent-based system, highlighting that overly general knowledge bases have a limited ability to address region-specific nuances. These results underscore the urgent need for better dataset balancing and robust retrieval strategies to enhance LLM fact-checking capabilities, particularly in geographically diverse contexts.
Global-Liar: Factuality of LLMs over Time and Geographic Regions
Jan 31, 2024The increasing reliance on AI-driven solutions, particularly Large Language Models (LLMs) like the GPT series, for information retrieval highlights the critical need for their factuality and fairness, especially amidst the rampant spread of misinformation and disinformation online. Our study evaluates the factual accuracy, stability, and biases in widely adopted GPT models, including GPT-3.5 and GPT-4, contributing to reliability and integrity of AI-mediated information dissemination. We introduce 'Global-Liar,' a dataset uniquely balanced in terms of geographic and temporal representation, facilitating a more nuanced evaluation of LLM biases. Our analysis reveals that newer iterations of GPT models do not always equate to improved performance. Notably, the GPT-4 version from March demonstrates higher factual accuracy than its subsequent June release. Furthermore, a concerning bias is observed, privileging statements from the Global North over the Global South, thus potentially exacerbating existing informational inequities. Regions such as Africa and the Middle East are at a disadvantage, with much lower factual accuracy. The performance fluctuations over time suggest that model updates may not consistently benefit all regions equally. Our study also offers insights into the impact of various LLM configuration settings, such as binary decision forcing, model re-runs and temperature, on model's factuality. Models constrained to binary (true/false) choices exhibit reduced factuality compared to those allowing an 'unclear' option. Single inference at a low temperature setting matches the reliability of majority voting across various configurations. The insights gained highlight the need for culturally diverse and geographically inclusive model training and evaluation. This approach is key to achieving global equity in technology, distributing AI benefits fairly worldwide.
Unveiling the Sentinels: Assessing AI Performance in Cybersecurity Peer Review
Sep 11, 2023Peer review is the method employed by the scientific community for evaluating research advancements. In the field of cybersecurity, the practice of double-blind peer review is the de-facto standard. This paper touches on the holy grail of peer reviewing and aims to shed light on the performance of AI in reviewing for academic security conferences. Specifically, we investigate the predictability of reviewing outcomes by comparing the results obtained from human reviewers and machine-learning models. To facilitate our study, we construct a comprehensive dataset by collecting thousands of papers from renowned computer science conferences and the arXiv preprint website. Based on the collected data, we evaluate the prediction capabilities of ChatGPT and a two-stage classification approach based on the Doc2Vec model with various classifiers. Our experimental evaluation of review outcome prediction using the Doc2Vec-based approach performs significantly better than the ChatGPT and achieves an accuracy of over 90%. While analyzing the experimental results, we identify the potential advantages and limitations of the tested ML models. We explore areas within the paper-reviewing process that can benefit from automated support approaches, while also recognizing the irreplaceable role of human intellect in certain aspects that cannot be matched by state-of-the-art AI techniques.