 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning of Mixtures of Experts
Dec 15, 2023



In modern machine learning problems we deal with datasets that are either distributed by nature or potentially large for which distributing the computations is usually a standard way to proceed, since centralized algorithms are in general ineffective. We propose a distributed learning approach for mixtures of experts (MoE) models with an aggregation strategy to construct a reduction estimator from local estimators fitted parallelly to distributed subsets of the data. The aggregation is based on an optimal minimization of an expected transportation divergence between the large MoE composed of local estimators and the unknown desired MoE model. We show that the provided reduction estimator is consistent as soon as the local estimators to be aggregated are consistent, and its construction is performed by a proposed majorization-minimization (MM) algorithm that is computationally effective. We study the statistical and numerical properties for the proposed reduction estimator on experiments that demonstrate its performance compared to namely the global estimator constructed in a centralized way from the full dataset. For some situations, the computation time is more than ten times faster, for a comparable performance. Our source codes are publicly available on Github.
Functional mixture-of-experts for classification
Feb 28, 2022
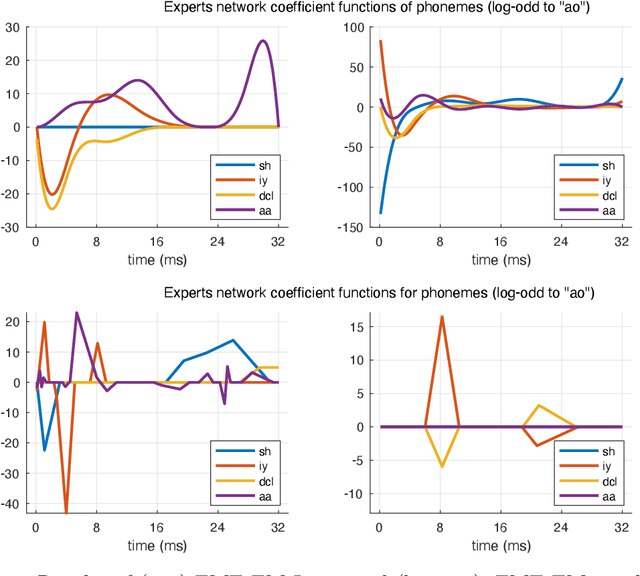
We develop a mixtures-of-experts (ME) approach to the multiclass classification where the predictors are univariate functions. It consists of a ME model in which both the gating network and the experts network are constructed upon multinomial logistic activation functions with functional inputs. We perform a regularized maximum likelihood estimation in which the coefficient functions enjoy interpretable sparsity constraints on targeted derivatives. We develop an EM-Lasso like algorithm to compute the regularized MLE and evaluate the proposed approach on simulated and real data.
Functional Mixtures-of-Experts
Feb 04, 2022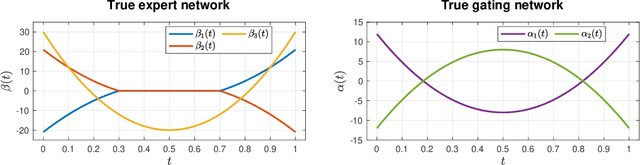
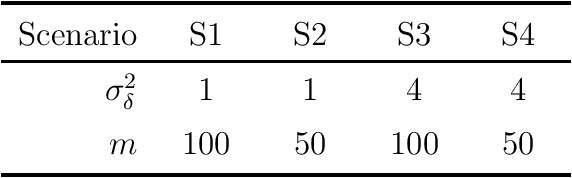
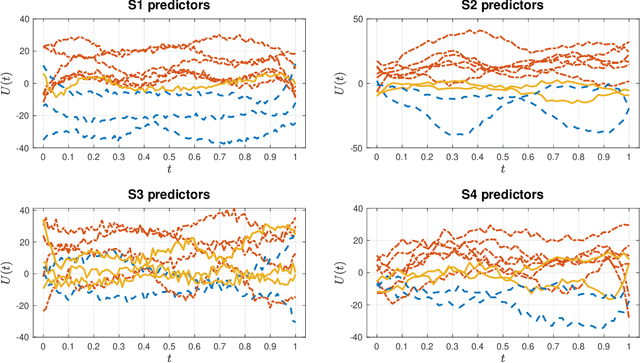
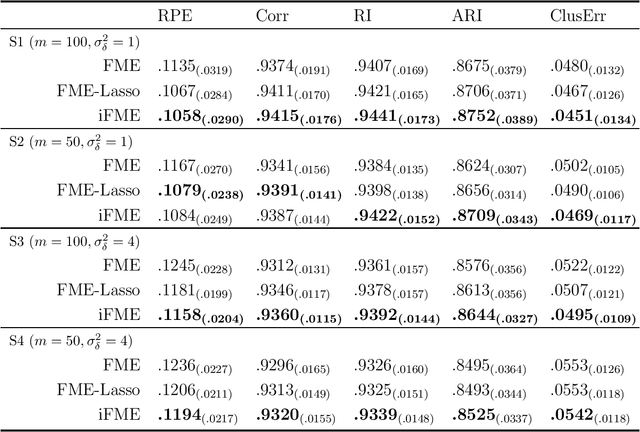
We consider the statistical analysis of heterogeneous data for clustering and prediction purposes, in situations where the observations include functions, typically time series. We extend the modeling with Mixtures-of-Experts (ME), as a framework of choice in modeling heterogeneity in data for prediction and clustering with vectorial observations, to this functional data analysis context. We first present a new family of functional ME (FME) models, in which the predictors are potentially noisy observations, from entire functions, and the data generating process of the pair predictor and the real response, is governed by a hidden discrete variable representing an unknown partition, leading to complex situations to which the standard ME framework is not adapted. Second, we provide sparse and interpretable functional representations of the FME models, thanks to Lasso-like regularizations, notably on the derivatives of the underlying functional parameters of the model, projected onto a set of continuous basis functions. We develop dedicated expectation--maximization algorithms for Lasso-like regularized maximum-likelihood parameter estimation strategies, to encourage sparse and interpretable solutions. The proposed FME models and the developed EM-Lasso algorithms are studied in simulated scenarios and in applications to two real data sets, and the obtained results demonstrate their performance in accurately capturing complex nonlinear relationships between the response and the functional predictor, and in clustering.