 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Dynamic Modeling and Learning for Spatiotemporal Data Forecasting
Mar 06, 2025



This paper presents an advanced Federated Learning (FL) framework for forecasting complex spatiotemporal data, improving upon recent state-of-the-art models. In the proposed approach, the original Gated Recurrent Unit (GRU) module within previous Dynamic Spatial--Temporal Graph Convolutional Recurrent Network (DSTGCRN) modeling is first replaced with a Long Short-Term Memory (LSTM) network, enabling the resulting model to more effectively capture long-term dependencies inherent to time series data. The resulting architecture significantly improves the model's capacity to handle complex temporal patterns in diverse forecasting applications. Furthermore, the proposed FL framework integrates a novel Client-Side Validation (CSV) mechanism, introducing a critical validation step at the client level before incorporating aggregated parameters from the central server into local models. This ensures that only the most effective updates are adopted, improving both the robustness and accuracy of the forecasting model across clients. The efficiency of our approach is demonstrated through extensive experiments on real-world applications, including public datasets for multimodal transport demand forecasting and private datasets for Origin-Destination (OD) matrix forecasting in urban areas. The results demonstrate substantial improvements over conventional methods, highlighting the framework's ability to capture complex spatiotemporal dependencies while preserving data privacy. This work not only provides a scalable and privacy-preserving solution for real-time, region-specific forecasting and management but also underscores the potential of leveraging distributed data sources in a FL context. We provide our algorithms as open-source on GitHub.
Distributed Learning of Mixtures of Experts
Dec 15, 2023



In modern machine learning problems we deal with datasets that are either distributed by nature or potentially large for which distributing the computations is usually a standard way to proceed, since centralized algorithms are in general ineffective. We propose a distributed learning approach for mixtures of experts (MoE) models with an aggregation strategy to construct a reduction estimator from local estimators fitted parallelly to distributed subsets of the data. The aggregation is based on an optimal minimization of an expected transportation divergence between the large MoE composed of local estimators and the unknown desired MoE model. We show that the provided reduction estimator is consistent as soon as the local estimators to be aggregated are consistent, and its construction is performed by a proposed majorization-minimization (MM) algorithm that is computationally effective. We study the statistical and numerical properties for the proposed reduction estimator on experiments that demonstrate its performance compared to namely the global estimator constructed in a centralized way from the full dataset. For some situations, the computation time is more than ten times faster, for a comparable performance. Our source codes are publicly available on Github.
Data-driven Reachability using Christoffel Functions and Conformal Prediction
Sep 16, 2023An important mathematical tool in the analysis of dynamical systems is the approximation of the reach set, i.e., the set of states reachable after a given time from a given initial state. This set is difficult to compute for complex systems even if the system dynamics are known and given by a system of ordinary differential equations with known coefficients. In practice, parameters are often unknown and mathematical models difficult to obtain. Data-based approaches are promised to avoid these difficulties by estimating the reach set based on a sample of states. If a model is available, this training set can be obtained through numerical simulation. In the absence of a model, real-life observations can be used instead. A recently proposed approach for data-based reach set approximation uses Christoffel functions to approximate the reach set. Under certain assumptions, the approximation is guaranteed to converge to the true solution. In this paper, we improve upon these results by notably improving the sample efficiency and relaxing some of the assumptions by exploiting statistical guarantees from conformal prediction with training and calibration sets. In addition, we exploit an incremental way to compute the Christoffel function to avoid the calibration set while maintaining the statistical convergence guarantees. Furthermore, our approach is robust to outliers in the training and calibration set.
Functional Mixtures-of-Experts
Feb 04, 2022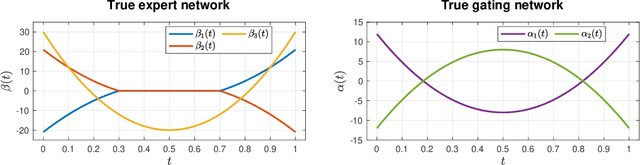
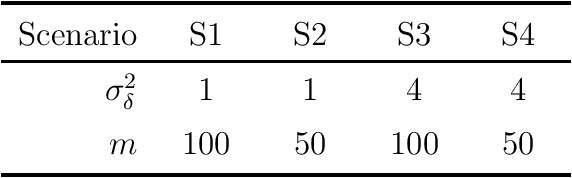
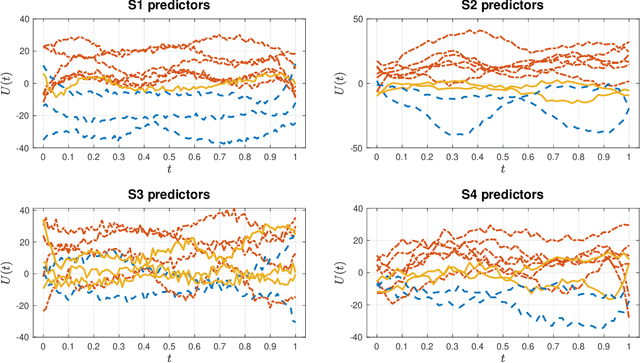
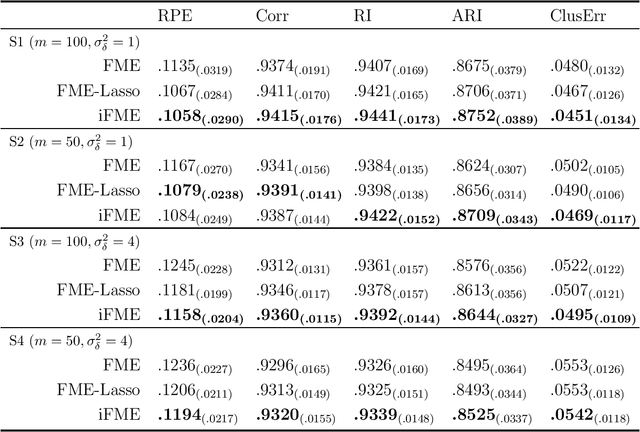
We consider the statistical analysis of heterogeneous data for clustering and prediction purposes, in situations where the observations include functions, typically time series. We extend the modeling with Mixtures-of-Experts (ME), as a framework of choice in modeling heterogeneity in data for prediction and clustering with vectorial observations, to this functional data analysis context. We first present a new family of functional ME (FME) models, in which the predictors are potentially noisy observations, from entire functions, and the data generating process of the pair predictor and the real response, is governed by a hidden discrete variable representing an unknown partition, leading to complex situations to which the standard ME framework is not adapted. Second, we provide sparse and interpretable functional representations of the FME models, thanks to Lasso-like regularizations, notably on the derivatives of the underlying functional parameters of the model, projected onto a set of continuous basis functions. We develop dedicated expectation--maximization algorithms for Lasso-like regularized maximum-likelihood parameter estimation strategies, to encourage sparse and interpretable solutions. The proposed FME models and the developed EM-Lasso algorithms are studied in simulated scenarios and in applications to two real data sets, and the obtained results demonstrate their performance in accurately capturing complex nonlinear relationships between the response and the functional predictor, and in clustering.