 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Instance Learning for Brain Tumor Detection from Magnetic Resonance Spectroscopy Data
Dec 16, 2021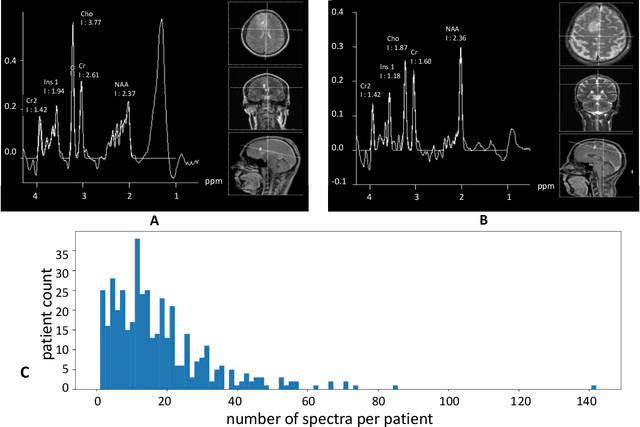
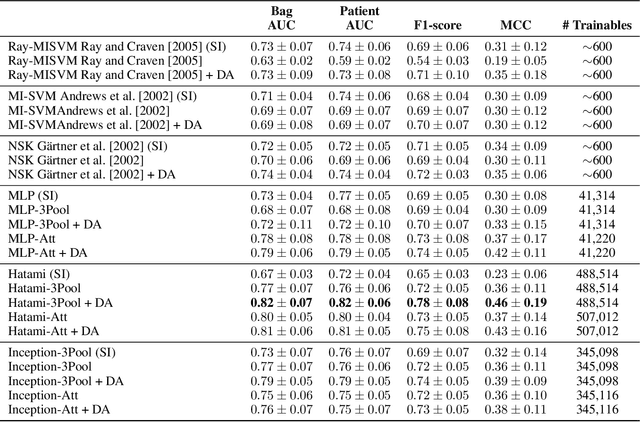
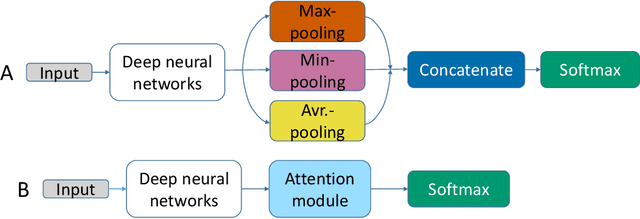
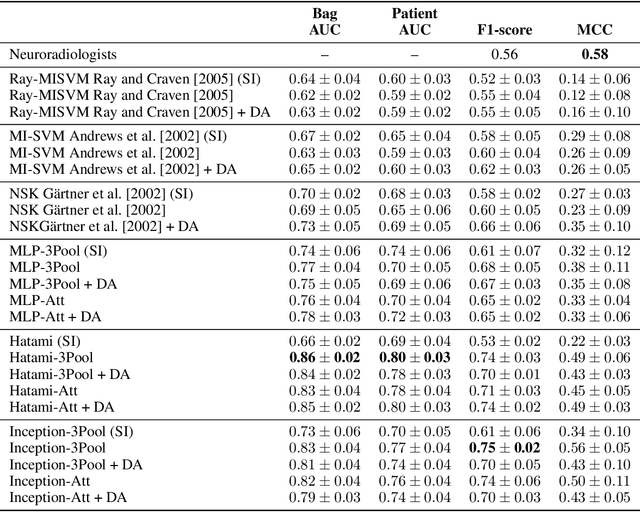
We apply deep learning (DL) on Magnetic resonance spectroscopy (MRS) data for the task of brain tumor detection. Medical applications often suffer from data scarcity and corruption by noise. Both of these problems are prominent in our data set. Furthermore, a varying number of spectra are available for the different patients. We address these issues by considering the task as a multiple instance learning (MIL) problem. Specifically, we aggregate multiple spectra from the same patient into a "bag" for classification and apply data augmentation techniques. To achieve the permutation invariance during the process of bagging, we proposed two approaches: (1) to apply min-, max-, and average-pooling on the features of all samples in one bag and (2) to apply an attention mechanism. We tested these two approaches on multiple neural network architectures. We demonstrate that classification performance is significantly improved when training on multiple instances rather than single spectra. We propose a simple oversampling data augmentation method and show that it could further improve the performance. Finally, we demonstrate that our proposed model outperforms manual classification by neuroradiologists according to most performance metrics.
Human-Expert-Level Brain Tumor Detection Using Deep Learning with Data Distillation and Augmentation
Jul 16, 2020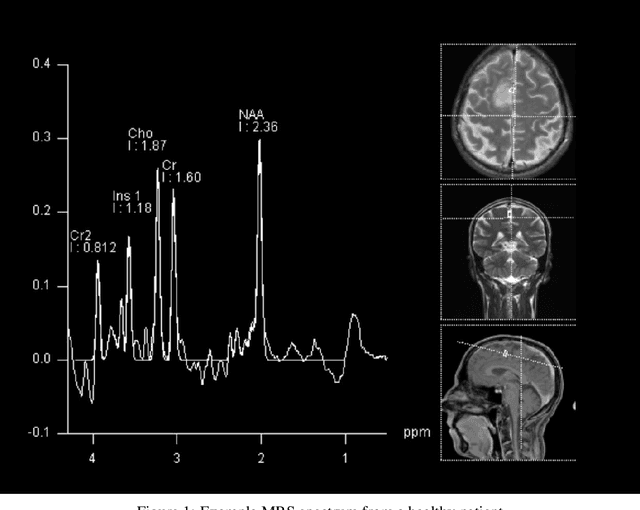
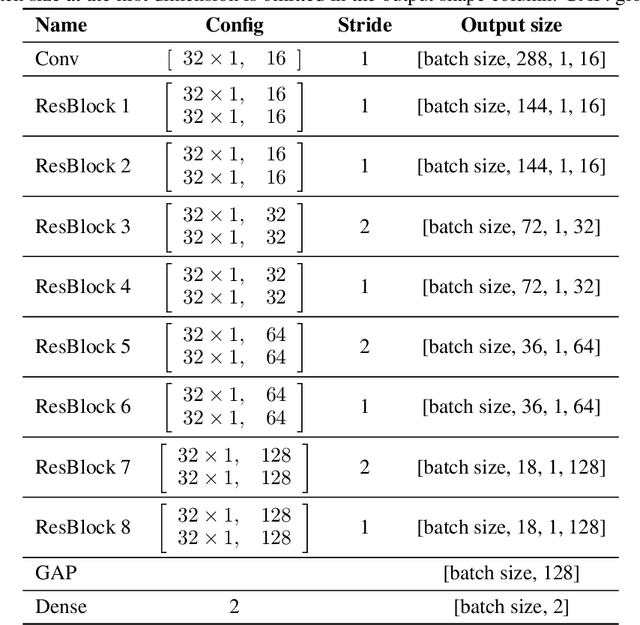
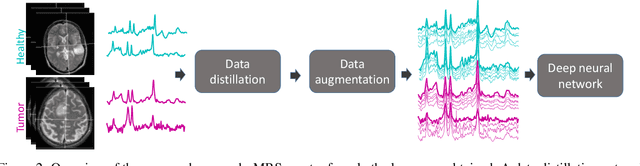
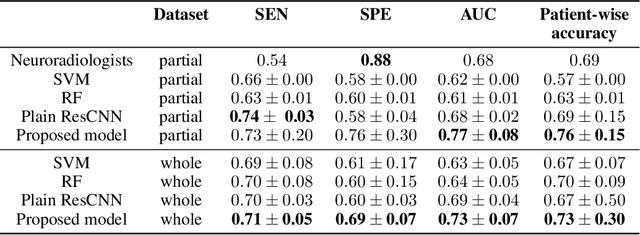
The application of Deep Learning (DL) for medical diagnosis is often hampered by two problems. First, the amount of training data may be scarce, as it is limited by the number of patients who have acquired the condition to be diagnosed. Second, the training data may be corrupted by various types of noise. Here, we study the problem of brain tumor detection from magnetic resonance spectroscopy (MRS) data, where both types of problems are prominent. To overcome these challenges, we propose a new method for training a deep neural network that distills particularly representative training examples and augments the training data by mixing these samples from one class with those from the same and other classes to create additional training samples. We demonstrate that this technique substantially improves performance, allowing our method to reach human-expert-level accuracy with just a few thousand training examples. Interestingly, the network learns to rely on features of the data that are usually ignored by human experts, suggesting new directions for future research.