 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical and empirical analysis of a fast algorithm for extracting polygons from signed distance bounds
Nov 10, 2021
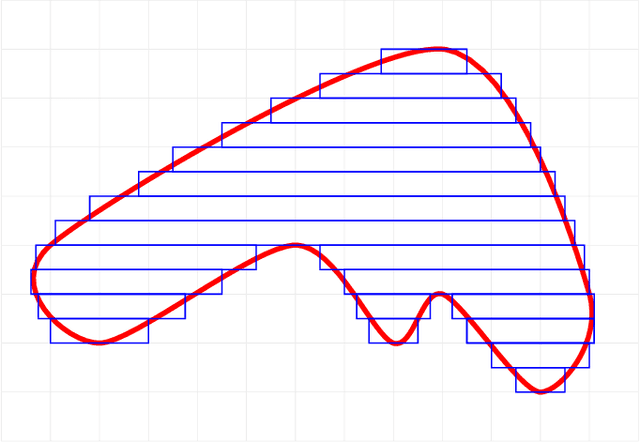

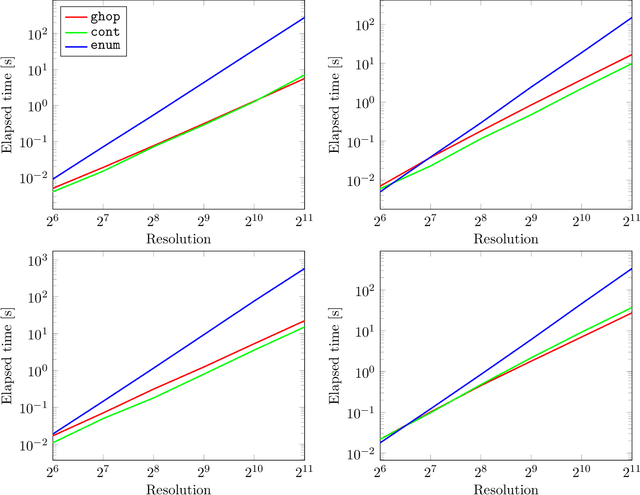
We investigate an asymptotically fast method for transforming signed distance bounds into polygon meshes. This is achieved by combining sphere tracing (also known as ray marching) and one of the traditional polygonization schemes (e.g., Marching cubes). Let us call this approach Gridhopping. We provide theoretical and experimental evidence that it is of the $O(N^2\log N)$ computational complexity for a polygonization grid with $N^3$ cells. The algorithm is tested on both a set of primitive shapes as well as signed distance fields generated from point clouds by machine learning. Given its speed, simplicity and portability, we argue that it could prove useful during the modelling stage as well as in shape compression for storage. The code is available here: https://github.com/nenadmarkus/gridhopping
Memory-Efficient Global Refinement of Decision-Tree Ensembles and its Application to Face Alignment
Sep 03, 2018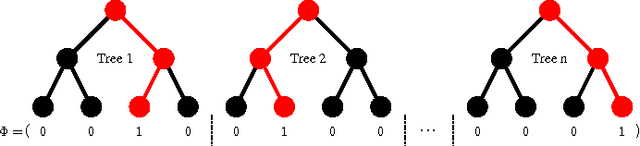
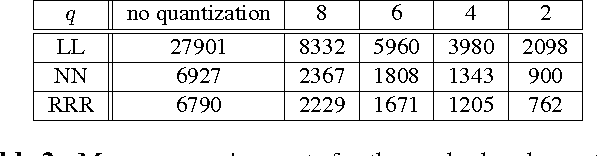
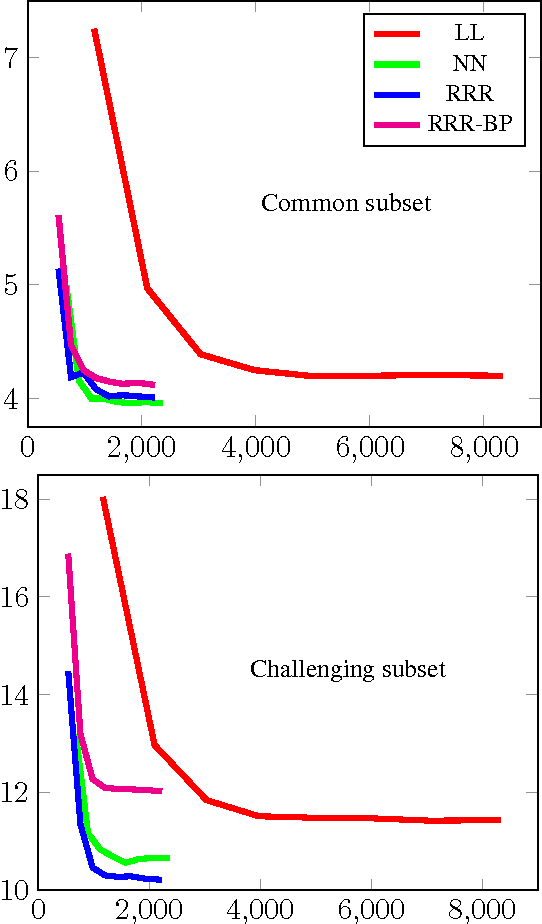
Ren et al. recently introduced a method for aggregating multiple decision trees into a strong predictor by interpreting a path taken by a sample down each tree as a binary vector and performing linear regression on top of these vectors stacked together. They provided experimental evidence that the method offers advantages over the usual approaches for combining decision trees (random forests and boosting). The method truly shines when the regression target is a large vector with correlated dimensions, such as a 2D face shape represented with the positions of several facial landmarks. However, we argue that their basic method is not applicable in many practical scenarios due to large memory requirements. This paper shows how this issue can be solved through the use of quantization and architectural changes of the predictor that maps decision tree-derived encodings to the desired output.
Learning Local Descriptors by Optimizing the Keypoint-Correspondence Criterion: Applications to Face Matching, Learning from Unlabeled Videos and 3D-Shape Retrieval
May 22, 2018



Current best local descriptors are learned on a large dataset of matching and non-matching keypoint pairs. However, data of this kind is not always available since detailed keypoint correspondences can be hard to establish. On the other hand, we can often obtain labels for pairs of keypoint bags. For example, keypoint bags extracted from two images of the same object under different views form a matching pair, and keypoint bags extracted from images of different objects form a non-matching pair. On average, matching pairs should contain more corresponding keypoints than non-matching pairs. We describe an end-to-end differentiable architecture that enables the learning of local keypoint descriptors from such weakly-labeled data. Additionally, we discuss how to improve the method by incorporating the procedure of mining hard negatives. We also show how can our approach be used to learn convolutional features from unlabeled video signals and 3D models. Our implementation is available at https://github.com/nenadmarkus/wlrn
Constructing Binary Descriptors with a Stochastic Hill Climbing Search
Jul 16, 2015
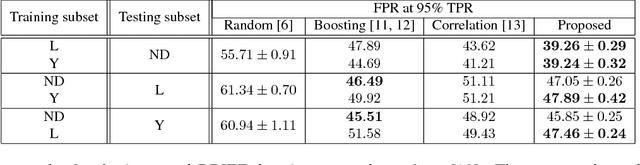

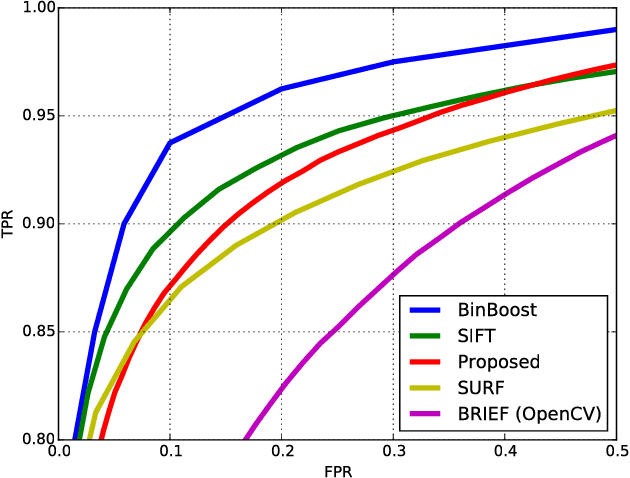
Binary descriptors of image patches provide processing speed advantages and require less storage than methods that encode the patch appearance with a vector of real numbers. We provide evidence that, despite its simplicity, a stochastic hill climbing bit selection procedure for descriptor construction defeats recently proposed alternatives on a standard discriminative power benchmark. The method is easy to implement and understand, has no free parameters that need fine tuning, and runs fast.
Fast Localization of Facial Landmark Points
Jan 20, 2015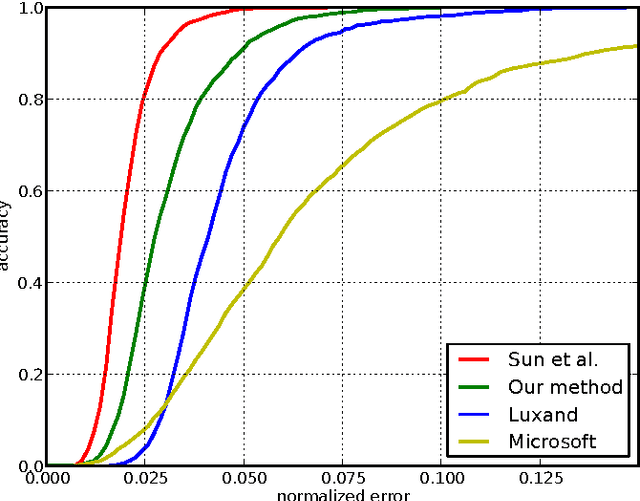
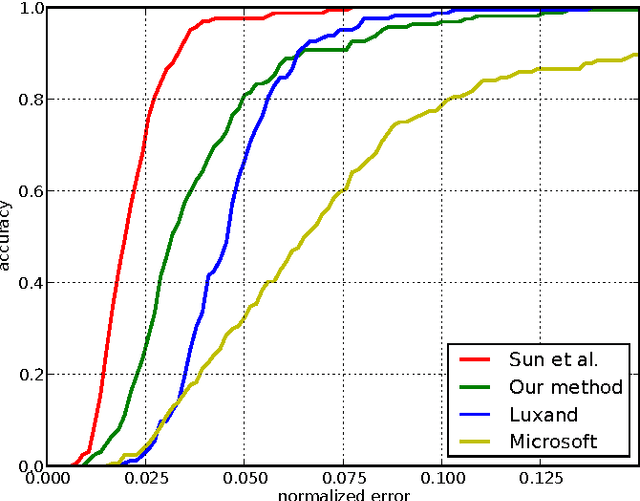
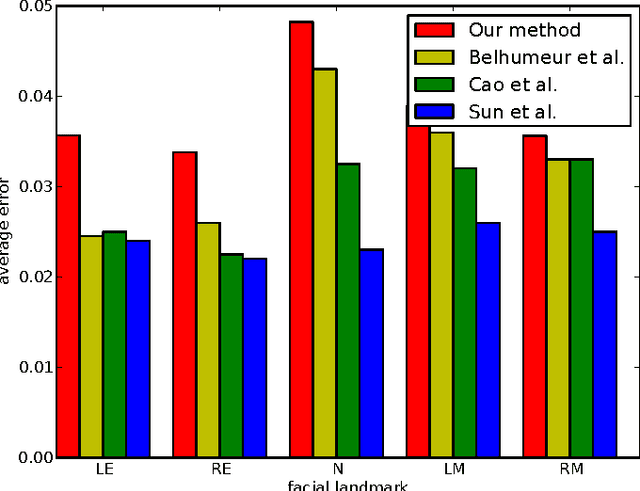
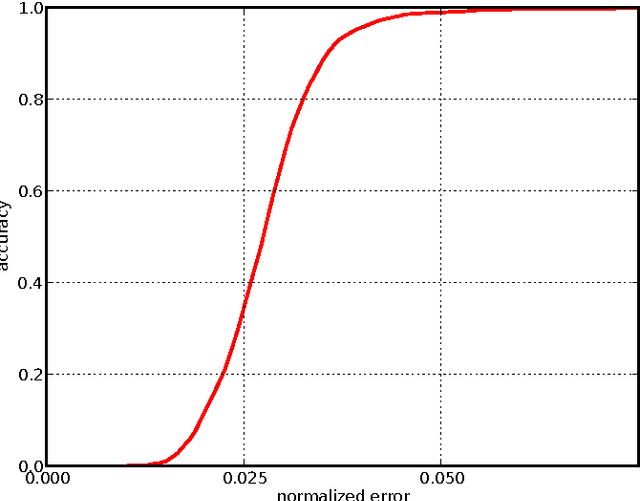
Localization of salient facial landmark points, such as eye corners or the tip of the nose, is still considered a challenging computer vision problem despite recent efforts. This is especially evident in unconstrained environments, i.e., in the presence of background clutter and large head pose variations. Most methods that achieve state-of-the-art accuracy are slow, and, thus, have limited applications. We describe a method that can accurately estimate the positions of relevant facial landmarks in real-time even on hardware with limited processing power, such as mobile devices. This is achieved with a sequence of estimators based on ensembles of regression trees. The trees use simple pixel intensity comparisons in their internal nodes and this makes them able to process image regions very fast. We test the developed system on several publicly available datasets and analyse its processing speed on various devices. Experimental results show that our method has practical value.
Object Detection with Pixel Intensity Comparisons Organized in Decision Trees
Aug 19, 2014


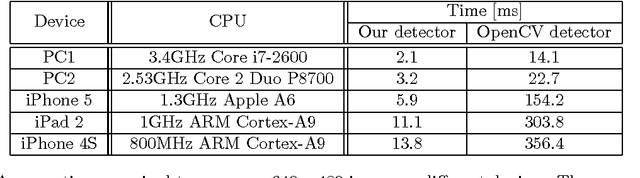
We describe a method for visual object detection based on an ensemble of optimized decision trees organized in a cascade of rejectors. The trees use pixel intensity comparisons in their internal nodes and this makes them able to process image regions very fast. Experimental analysis is provided through a face detection problem. The obtained results are encouraging and demonstrate that the method has practical value. Additionally, we analyse its sensitivity to noise and show how to perform fast rotation invariant object detection. Complete source code is provided at https://github.com/nenadmarkus/pico.