 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Global Refinement of Decision-Tree Ensembles and its Application to Face Alignment
Sep 03, 2018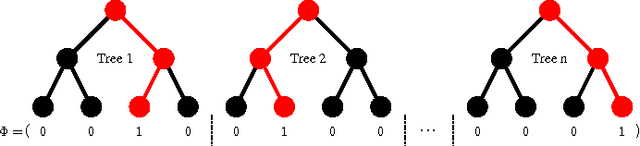
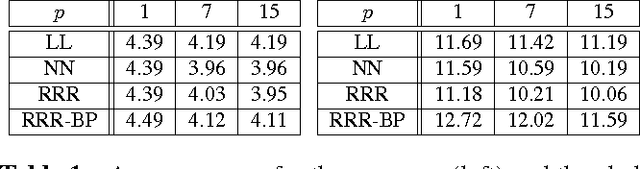
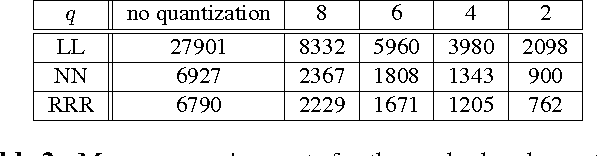
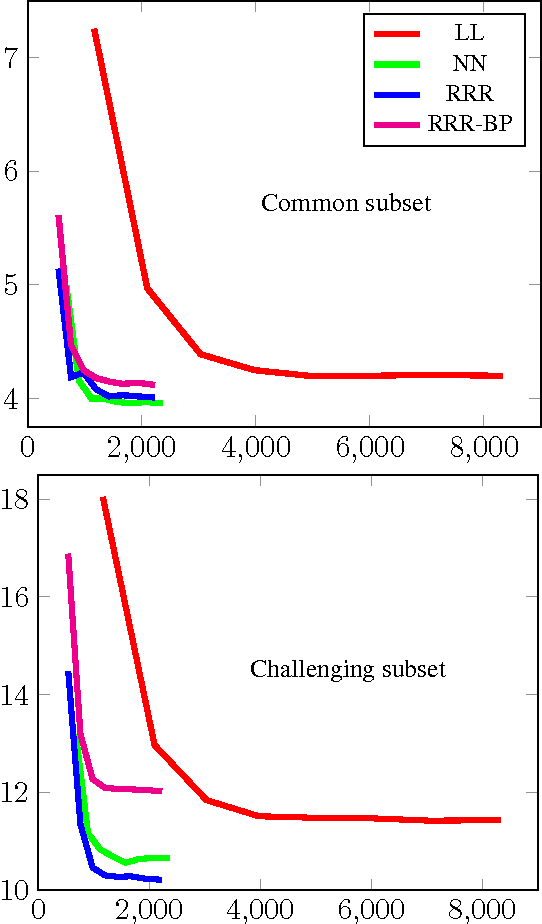
Ren et al. recently introduced a method for aggregating multiple decision trees into a strong predictor by interpreting a path taken by a sample down each tree as a binary vector and performing linear regression on top of these vectors stacked together. They provided experimental evidence that the method offers advantages over the usual approaches for combining decision trees (random forests and boosting). The method truly shines when the regression target is a large vector with correlated dimensions, such as a 2D face shape represented with the positions of several facial landmarks. However, we argue that their basic method is not applicable in many practical scenarios due to large memory requirements. This paper shows how this issue can be solved through the use of quantization and architectural changes of the predictor that maps decision tree-derived encodings to the desired output.