 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Shift Mixing -- Beyond Dense Attention in Transformers
Jan 30, 2026Since the introduction of the Transformer architecture for large language models, the softmax-based attention layer has faced increasing scrutinity due to its quadratic-time computational complexity. Attempts have been made to replace it with less complex methods, at the cost of reduced performance in most cases. We introduce Hierarchical Shift Mixing (HSM), a general framework for token mixing that distributes pairwise token interactions across Transformer layers rather than computing them densely within each layer. HSM enables linear-time complexity while remaining agnostic to the specific mixing function. We show that even simple HSM variants achieve performance close to softmax attention, and that hybrid architectures combining HSM with softmax attention can outperform a GPT-style Transformer baseline while reducing computational cost during both training and inference.
Local Approximations, Real Interpolation and Machine Learning
Jul 15, 2022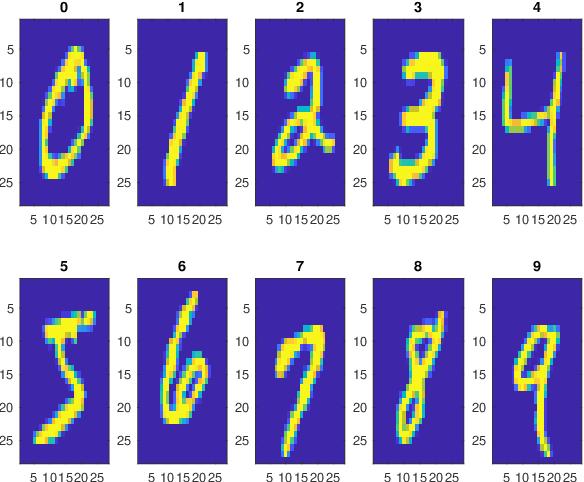



We suggest a novel classification algorithm that is based on local approximations and explain its connections with Artificial Neural Networks (ANNs) and Nearest Neighbour classifiers. We illustrate it on the datasets MNIST and EMNIST of images of handwritten digits. We use the dataset MNIST to find parameters of our algorithm and apply it with these parameters to the challenging EMNIST dataset. It is demonstrated that the algorithm misclassifies 0.42% of the images of EMNIST and therefore significantly outperforms predictions by humans and shallow artificial neural networks (ANNs with few hidden layers) that both have more than 1.3% of errors
An Improved Nearest Neighbour Classifier
Apr 27, 2022



A windowed version of the Nearest Neighbour (WNN) classifier for images is described. While its construction is inspired by the architecture of Artificial Neural Networks, the underlying theoretical framework is based on approximation theory. We illustrate WNN on the datasets MNIST and EMNIST of images of handwritten digits. In order to calibrate the parameters of WNN, we first study it on the classical MNIST dataset. We then apply WNN with these parameters to the challenging EMNIST dataset. It is demonstrated that WNN misclassifies 0.42% of the images of EMNIST and therefore significantly outperforms predictions by humans and shallow ANNs that both have more than 1.3% of errors.
Fast Localization of Facial Landmark Points
Jan 20, 2015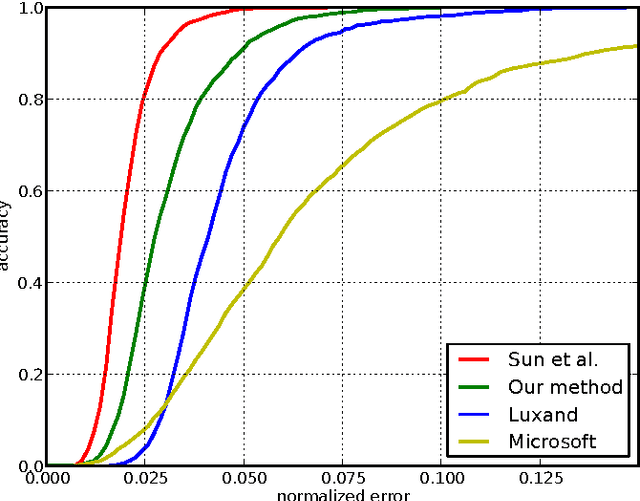
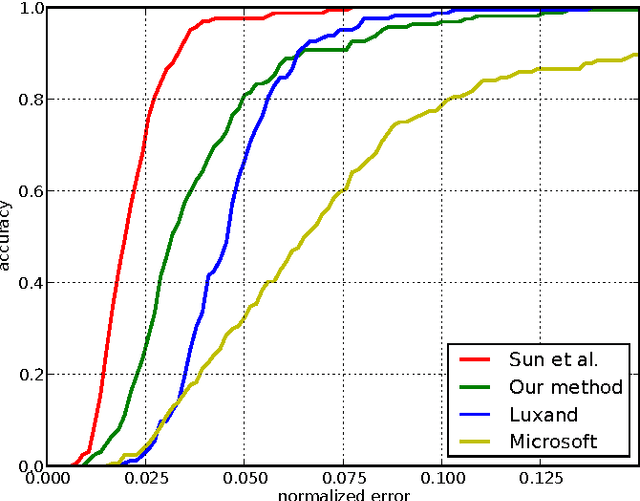
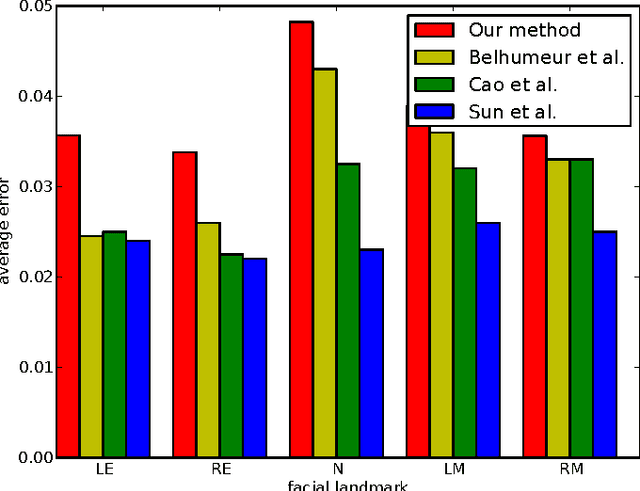
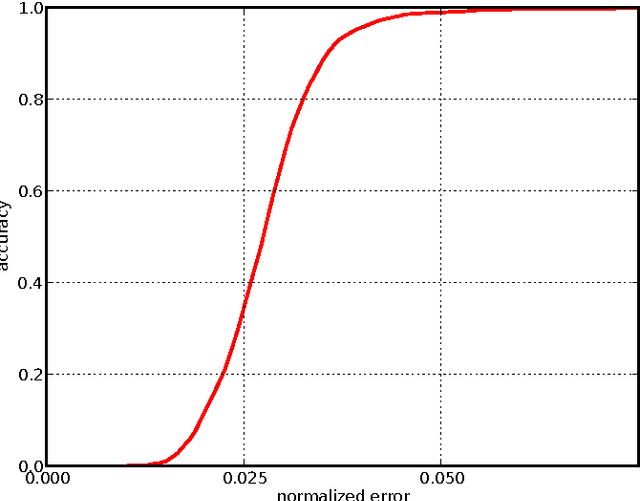
Localization of salient facial landmark points, such as eye corners or the tip of the nose, is still considered a challenging computer vision problem despite recent efforts. This is especially evident in unconstrained environments, i.e., in the presence of background clutter and large head pose variations. Most methods that achieve state-of-the-art accuracy are slow, and, thus, have limited applications. We describe a method that can accurately estimate the positions of relevant facial landmarks in real-time even on hardware with limited processing power, such as mobile devices. This is achieved with a sequence of estimators based on ensembles of regression trees. The trees use simple pixel intensity comparisons in their internal nodes and this makes them able to process image regions very fast. We test the developed system on several publicly available datasets and analyse its processing speed on various devices. Experimental results show that our method has practical value.
Object Detection with Pixel Intensity Comparisons Organized in Decision Trees
Aug 19, 2014


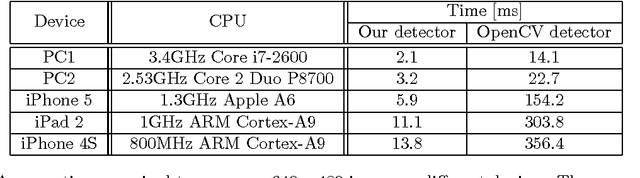
We describe a method for visual object detection based on an ensemble of optimized decision trees organized in a cascade of rejectors. The trees use pixel intensity comparisons in their internal nodes and this makes them able to process image regions very fast. Experimental analysis is provided through a face detection problem. The obtained results are encouraging and demonstrate that the method has practical value. Additionally, we analyse its sensitivity to noise and show how to perform fast rotation invariant object detection. Complete source code is provided at https://github.com/nenadmarkus/pico.