 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKlout Topics for Modeling Interests and Expertise of Users Across Social Networks
Oct 26, 2017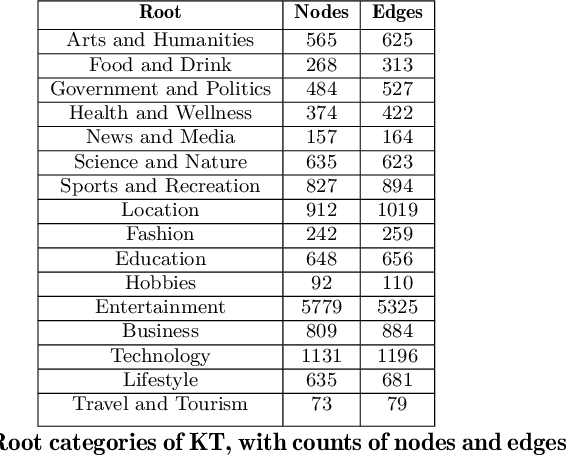
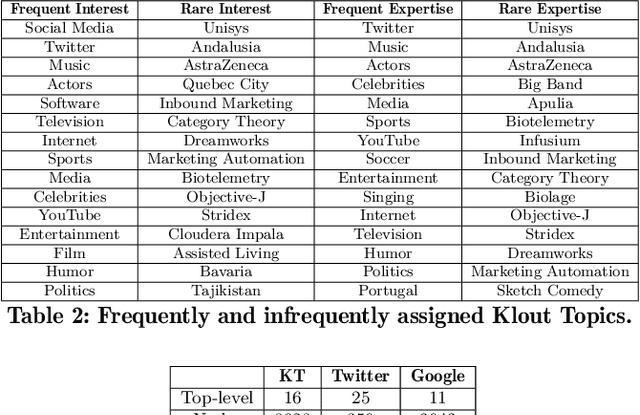
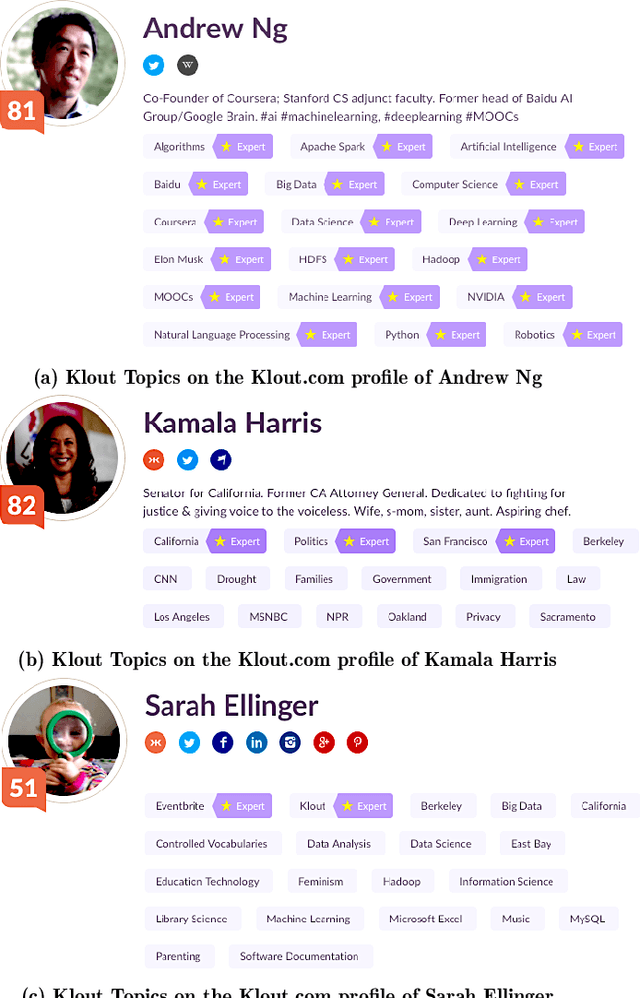
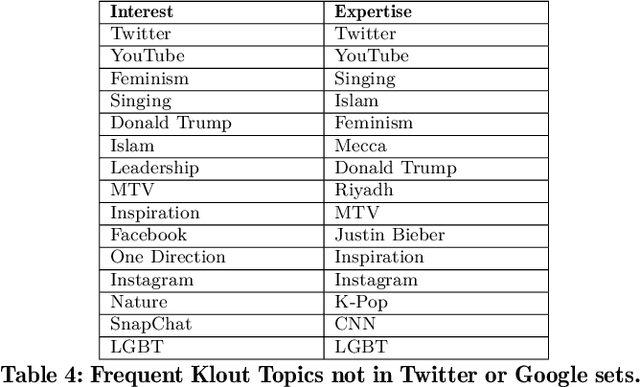
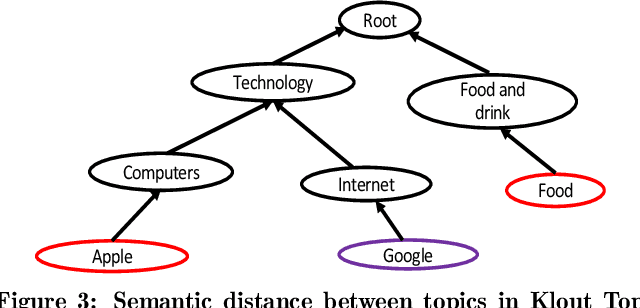
This paper presents Klout Topics, a lightweight ontology to describe social media users' topics of interest and expertise. Klout Topics is designed to: be human-readable and consumer-friendly; cover multiple domains of knowledge in depth; and promote data extensibility via knowledge base entities. We discuss why this ontology is well-suited for text labeling and interest modeling applications, and how it compares to available alternatives. We show its coverage against common social media interest sets, and examples of how it is used to model the interests of over 780M social media users on Klout.com. Finally, we open the ontology for external use.
Analyzing users' sentiment towards popular consumer industries and brands on Twitter
Sep 21, 2017

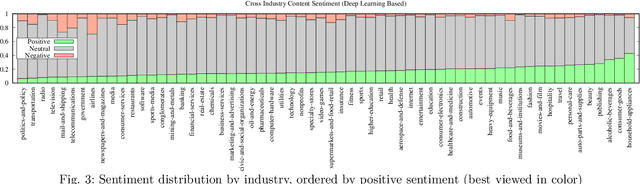
Social media serves as a unified platform for users to express their thoughts on subjects ranging from their daily lives to their opinion on consumer brands and products. These users wield an enormous influence in shaping the opinions of other consumers and influence brand perception, brand loyalty and brand advocacy. In this paper, we analyze the opinion of 19M Twitter users towards 62 popular industries, encompassing 12,898 enterprise and consumer brands, as well as associated subject matter topics, via sentiment analysis of 330M tweets over a period spanning a month. We find that users tend to be most positive towards manufacturing and most negative towards service industries. In addition, they tend to be more positive or negative when interacting with brands than generally on Twitter. We also find that sentiment towards brands within an industry varies greatly and we demonstrate this using two industries as use cases. In addition, we discover that there is no strong correlation between topic sentiments of different industries, demonstrating that topic sentiments are highly dependent on the context of the industry that they are mentioned in. We demonstrate the value of such an analysis in order to assess the impact of brands on social media. We hope that this initial study will prove valuable for both researchers and companies in understanding users' perception of industries, brands and associated topics and encourage more research in this field.
* 8 pages, 11 figures, 1 table, 2017 IEEE International Conference on Data Mining Workshops (ICDMW 2017), ICDM Sentiment Elicitation from Natural Text for Information Retrieval and Extraction (ICDM SENTIRE) 2017 workshop
Lithium NLP: A System for Rich Information Extraction from Noisy User Generated Text on Social Media
Jul 13, 2017

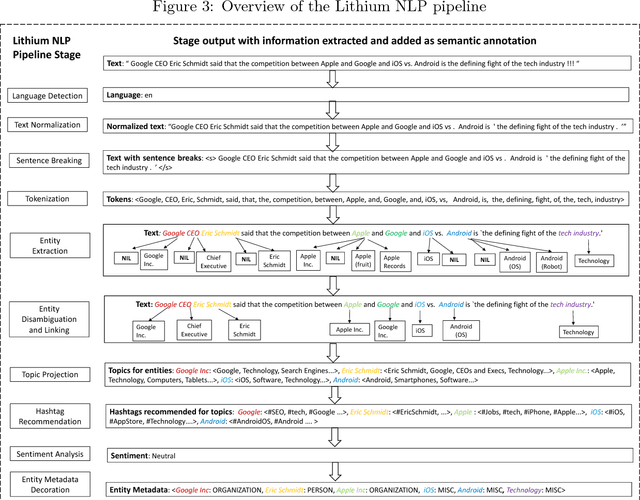
In this paper, we describe the Lithium Natural Language Processing (NLP) system - a resource-constrained, high- throughput and language-agnostic system for information extraction from noisy user generated text on social media. Lithium NLP extracts a rich set of information including entities, topics, hashtags and sentiment from text. We discuss several real world applications of the system currently incorporated in Lithium products. We also compare our system with existing commercial and academic NLP systems in terms of performance, information extracted and languages supported. We show that Lithium NLP is at par with and in some cases, outperforms state- of-the-art commercial NLP systems.
Global Entity Ranking Across Multiple Languages
Mar 17, 2017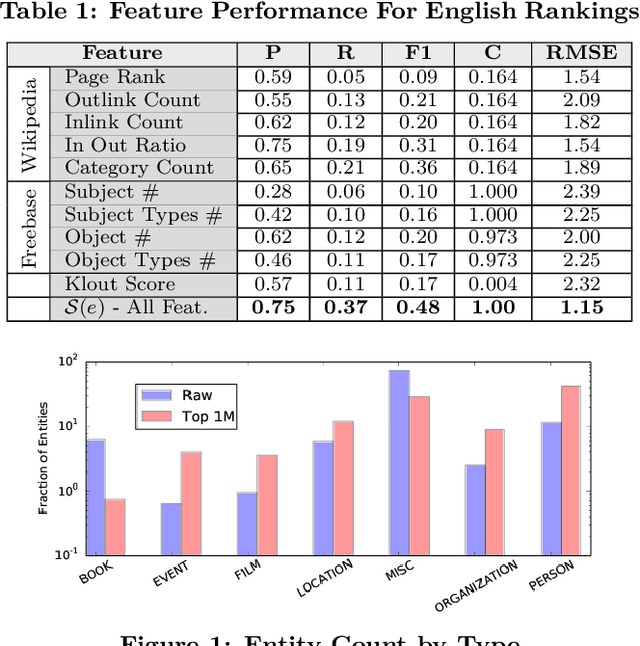
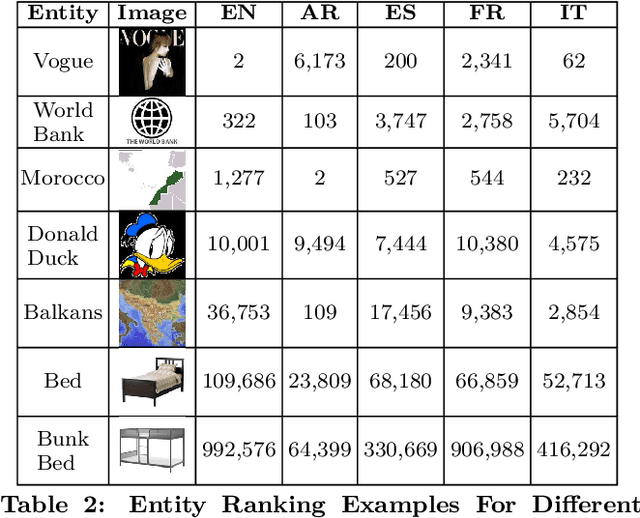
We present work on building a global long-tailed ranking of entities across multiple languages using Wikipedia and Freebase knowledge bases. We identify multiple features and build a model to rank entities using a ground-truth dataset of more than 10 thousand labels. The final system ranks 27 million entities with 75% precision and 48% F1 score. We provide performance evaluation and empirical evidence of the quality of ranking across languages, and open the final ranked lists for future research.
High-Throughput and Language-Agnostic Entity Disambiguation and Linking on User Generated Data
Mar 13, 2017
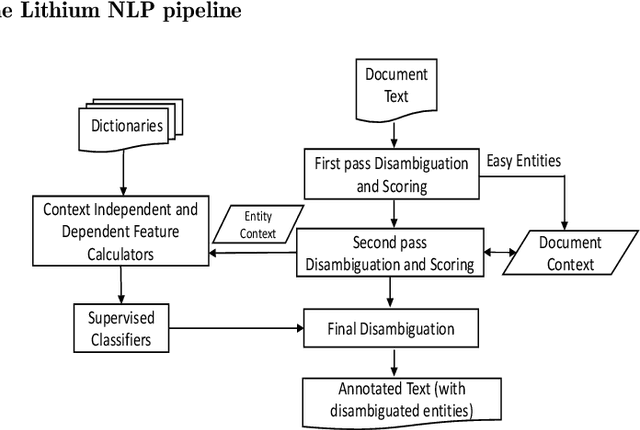

The Entity Disambiguation and Linking (EDL) task matches entity mentions in text to a unique Knowledge Base (KB) identifier such as a Wikipedia or Freebase id. It plays a critical role in the construction of a high quality information network, and can be further leveraged for a variety of information retrieval and NLP tasks such as text categorization and document tagging. EDL is a complex and challenging problem due to ambiguity of the mentions and real world text being multi-lingual. Moreover, EDL systems need to have high throughput and should be lightweight in order to scale to large datasets and run on off-the-shelf machines. More importantly, these systems need to be able to extract and disambiguate dense annotations from the data in order to enable an Information Retrieval or Extraction task running on the data to be more efficient and accurate. In order to address all these challenges, we present the Lithium EDL system and algorithm - a high-throughput, lightweight, language-agnostic EDL system that extracts and correctly disambiguates 75% more entities than state-of-the-art EDL systems and is significantly faster than them.
DAWT: Densely Annotated Wikipedia Texts across multiple languages
Mar 02, 2017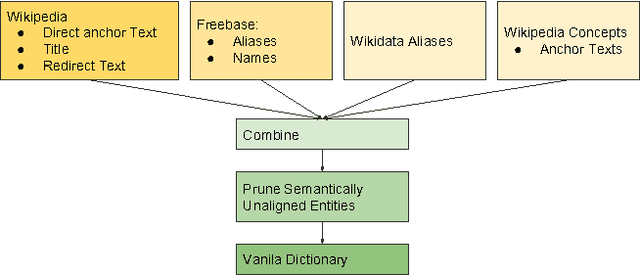



In this work, we open up the DAWT dataset - Densely Annotated Wikipedia Texts across multiple languages. The annotations include labeled text mentions mapping to entities (represented by their Freebase machine ids) as well as the type of the entity. The data set contains total of 13.6M articles, 5.0B tokens, 13.8M mention entity co-occurrences. DAWT contains 4.8 times more anchor text to entity links than originally present in the Wikipedia markup. Moreover, it spans several languages including English, Spanish, Italian, German, French and Arabic. We also present the methodology used to generate the dataset which enriches Wikipedia markup in order to increase number of links. In addition to the main dataset, we open up several derived datasets including mention entity co-occurrence counts and entity embeddings, as well as mappings between Freebase ids and Wikidata item ids. We also discuss two applications of these datasets and hope that opening them up would prove useful for the Natural Language Processing and Information Retrieval communities, as well as facilitate multi-lingual research.
Actionable and Political Text Classification using Word Embeddings and LSTM
Jul 13, 2016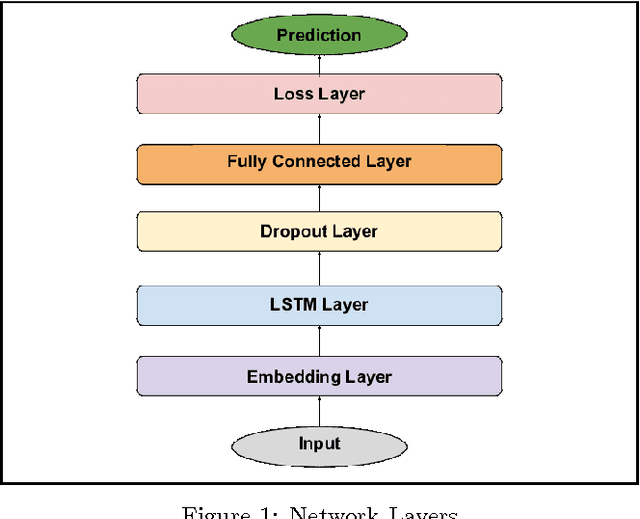
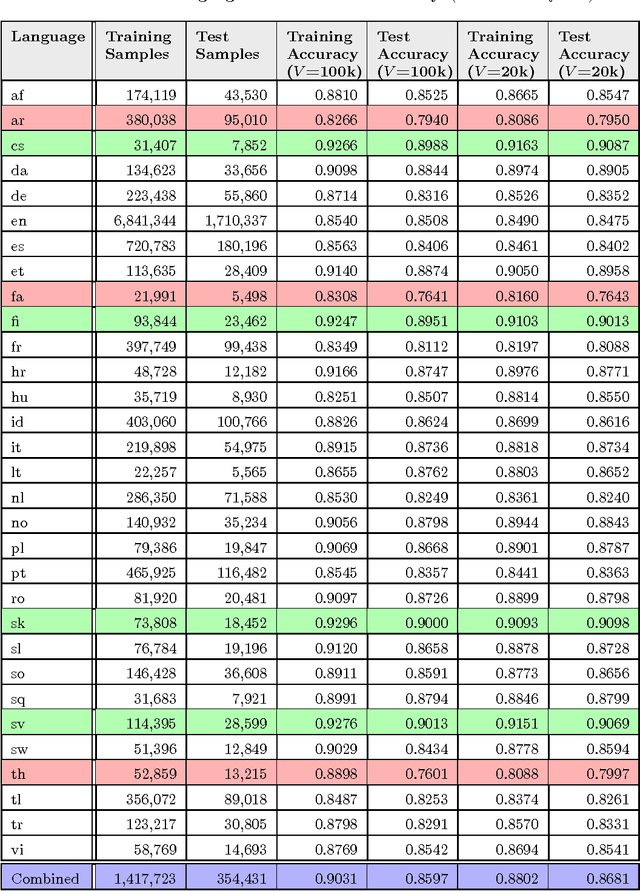
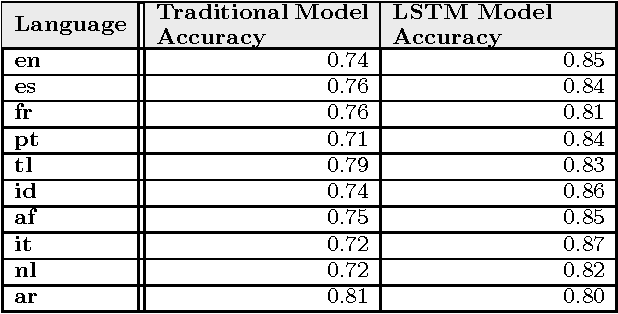
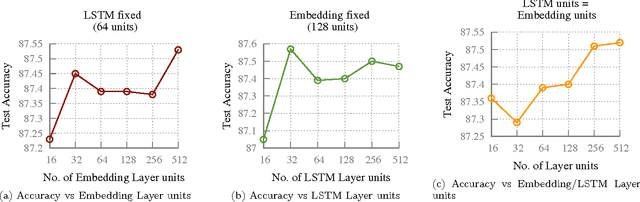
In this work, we apply word embeddings and neural networks with Long Short-Term Memory (LSTM) to text classification problems, where the classification criteria are decided by the context of the application. We examine two applications in particular. The first is that of Actionability, where we build models to classify social media messages from customers of service providers as Actionable or Non-Actionable. We build models for over 30 different languages for actionability, and most of the models achieve accuracy around 85%, with some reaching over 90% accuracy. We also show that using LSTM neural networks with word embeddings vastly outperform traditional techniques. Second, we explore classification of messages with respect to political leaning, where social media messages are classified as Democratic or Republican. The model is able to classify messages with a high accuracy of 87.57%. As part of our experiments, we vary different hyperparameters of the neural networks, and report the effect of such variation on the accuracy. These actionability models have been deployed to production and help company agents provide customer support by prioritizing which messages to respond to. The model for political leaning has been opened and made available for wider use.