Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Entity Ranking Across Multiple Languages
Paper and Code
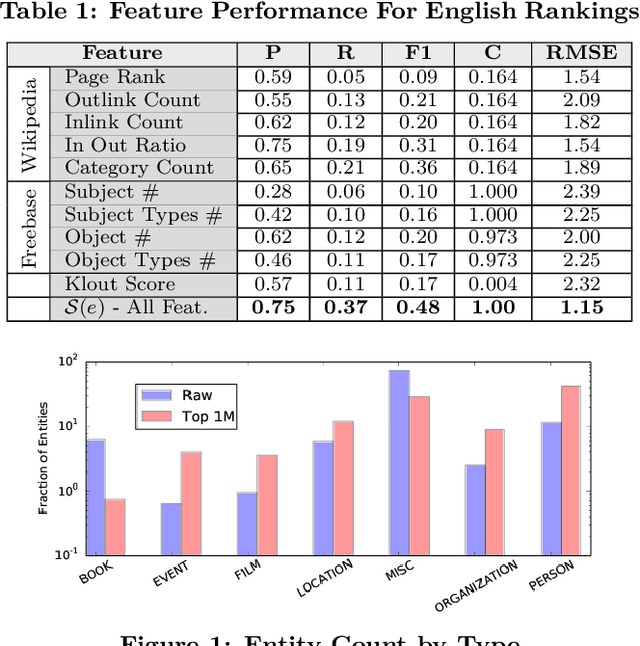
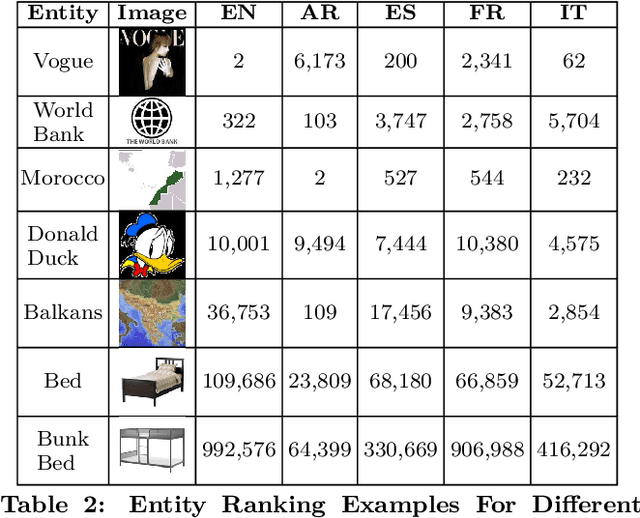
We present work on building a global long-tailed ranking of entities across multiple languages using Wikipedia and Freebase knowledge bases. We identify multiple features and build a model to rank entities using a ground-truth dataset of more than 10 thousand labels. The final system ranks 27 million entities with 75% precision and 48% F1 score. We provide performance evaluation and empirical evidence of the quality of ranking across languages, and open the final ranked lists for future research.
* 2 Pages, 1 Figure, 2 Tables, WWW2017 Companion, WWW 2017 Companion
View paper on