 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Throughput and Language-Agnostic Entity Disambiguation and Linking on User Generated Data
Paper and Code

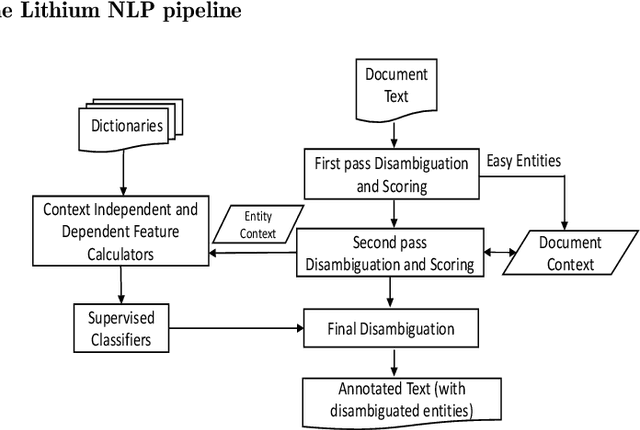

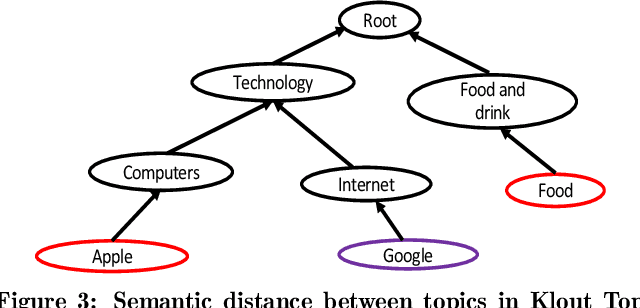
The Entity Disambiguation and Linking (EDL) task matches entity mentions in text to a unique Knowledge Base (KB) identifier such as a Wikipedia or Freebase id. It plays a critical role in the construction of a high quality information network, and can be further leveraged for a variety of information retrieval and NLP tasks such as text categorization and document tagging. EDL is a complex and challenging problem due to ambiguity of the mentions and real world text being multi-lingual. Moreover, EDL systems need to have high throughput and should be lightweight in order to scale to large datasets and run on off-the-shelf machines. More importantly, these systems need to be able to extract and disambiguate dense annotations from the data in order to enable an Information Retrieval or Extraction task running on the data to be more efficient and accurate. In order to address all these challenges, we present the Lithium EDL system and algorithm - a high-throughput, lightweight, language-agnostic EDL system that extracts and correctly disambiguates 75% more entities than state-of-the-art EDL systems and is significantly faster than them.