 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAWT: Densely Annotated Wikipedia Texts across multiple languages
Paper and Code
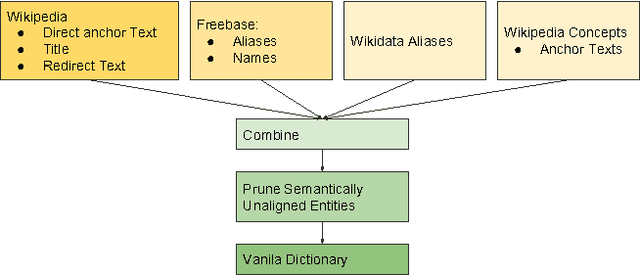



In this work, we open up the DAWT dataset - Densely Annotated Wikipedia Texts across multiple languages. The annotations include labeled text mentions mapping to entities (represented by their Freebase machine ids) as well as the type of the entity. The data set contains total of 13.6M articles, 5.0B tokens, 13.8M mention entity co-occurrences. DAWT contains 4.8 times more anchor text to entity links than originally present in the Wikipedia markup. Moreover, it spans several languages including English, Spanish, Italian, German, French and Arabic. We also present the methodology used to generate the dataset which enriches Wikipedia markup in order to increase number of links. In addition to the main dataset, we open up several derived datasets including mention entity co-occurrence counts and entity embeddings, as well as mappings between Freebase ids and Wikidata item ids. We also discuss two applications of these datasets and hope that opening them up would prove useful for the Natural Language Processing and Information Retrieval communities, as well as facilitate multi-lingual research.