 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reinforcement Learning with Human Assistance: An Argument for Human Subject Studies with HIPPO Gym
Feb 02, 2021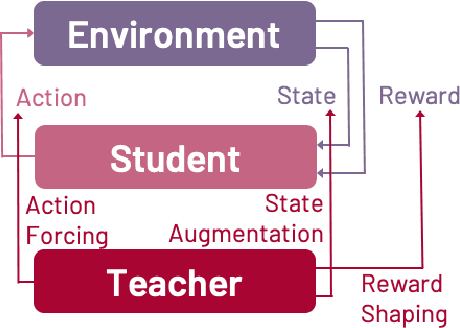
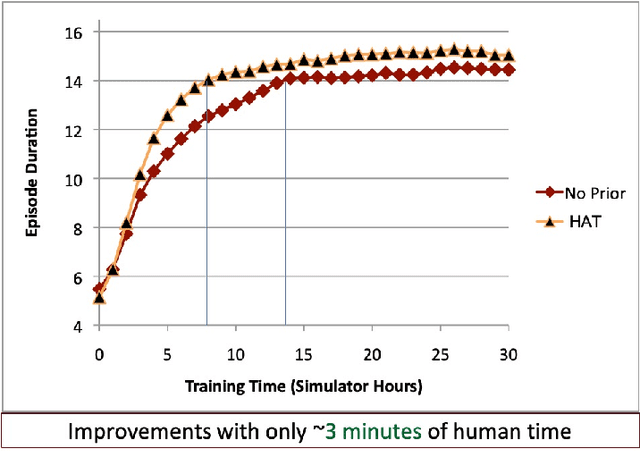

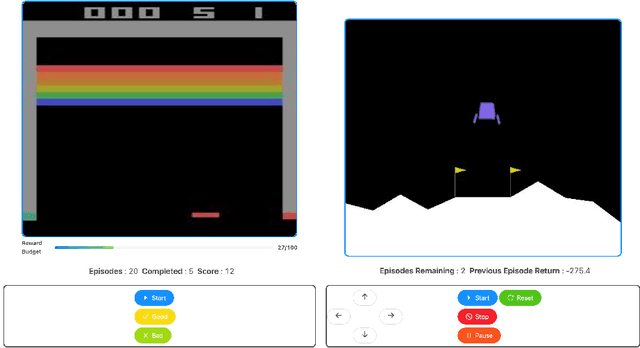
Reinforcement learning (RL) is a popular machine learning paradigm for game playing, robotics control, and other sequential decision tasks. However, RL agents often have long learning times with high data requirements because they begin by acting randomly. In order to better learn in complex tasks, this article argues that an external teacher can often significantly help the RL agent learn. OpenAI Gym is a common framework for RL research, including a large number of standard environments and agents, making RL research significantly more accessible. This article introduces our new open-source RL framework, the Human Input Parsing Platform for Openai Gym (HIPPO Gym), and the design decisions that went into its creation. The goal of this platform is to facilitate human-RL research, again lowering the bar so that more researchers can quickly investigate different ways that human teachers could assist RL agents, including learning from demonstrations, learning from feedback, or curriculum learning.
Human and Multi-Agent collaboration in a human-MARL teaming framework
Jun 12, 2020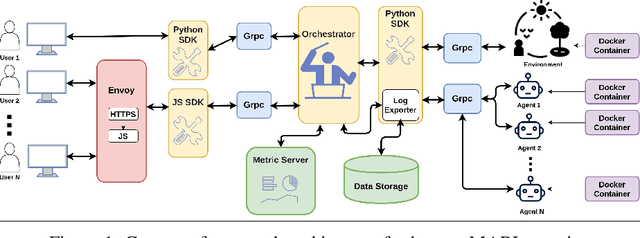
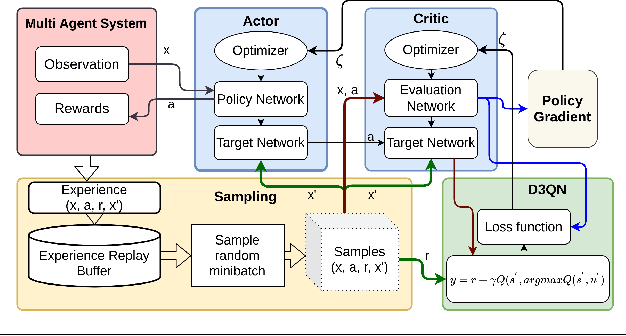
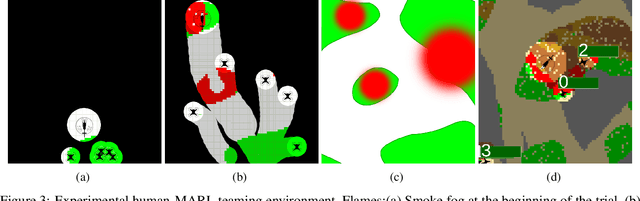
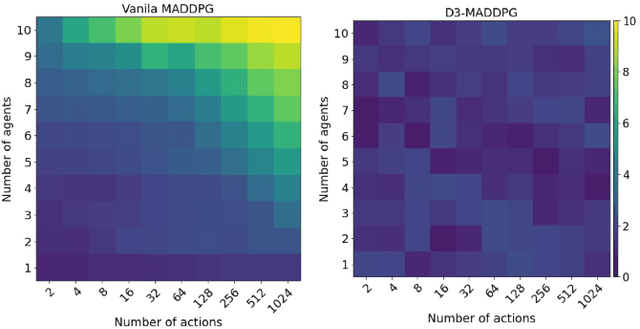
Collaborative multi-agent reinforcement learning (MARL) as a specific category of reinforcement learning provides effective results with agents learning from their observations, received rewards, and internal interactions between agents. However, centralized learning methods with a joint global policy in a highly dynamic environment present unique challenges in dealing with large amounts of information. This study proposes two innovative solutions to address the complexities of a collaboration between a human and multiple reinforcement learning (RL)-based agents (referred to thereafter as Human-MARL teaming) where the goals pursued cannot be achieved by a human alone or agents alone. The first innovation is the introduction of a new open-source MARL framework, called COGMENT, to unite humans and agents in real-time complex dynamic systems and efficiently leverage their interactions as a source of learning. The second innovation is our proposal of a new hybrid MARL method, named Dueling Double Deep Q learning MADDPG (D3-MADDPG) to allow agents to train decentralized policies parallelly in a joint centralized policy. This method can solve the overestimation problem in Q-learning methods of value-based MARL. We demonstrate these innovations by using a designed real-time environment with unmanned aerial vehicles driven by RL agents, collaborating with a human to fight fires. The team of RL agent drones autonomously look for fire seats and the human pilot douses the fires. The results of this study show that the proposed collaborative paradigm and the open-source framework leads to significant reductions in both human effort and exploration costs. Also, the results of the proposed hybrid MARL method shows that it effectively improves the learning process to achieve more reliable Q-values for each action, by decoupling the estimation between state value and advantage value.
Human AI interaction loop training: New approach for interactive reinforcement learning
Mar 09, 2020

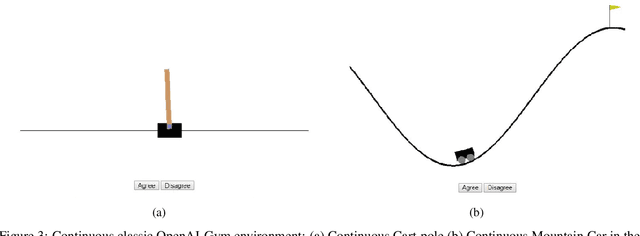
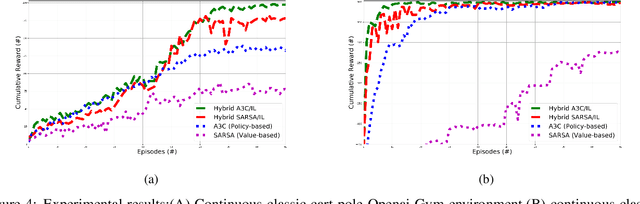
Reinforcement Learning (RL) in various decision-making tasks of machine learning provides effective results with an agent learning from a stand-alone reward function. However, it presents unique challenges with large amounts of environment states and action spaces, as well as in the determination of rewards. This complexity, coming from high dimensionality and continuousness of the environments considered herein, calls for a large number of learning trials to learn about the environment through Reinforcement Learning. Imitation Learning (IL) offers a promising solution for those challenges using a teacher. In IL, the learning process can take advantage of human-sourced assistance and/or control over the agent and environment. A human teacher and an agent learner are considered in this study. The teacher takes part in the agent training towards dealing with the environment, tackling a specific objective, and achieving a predefined goal. Within that paradigm, however, existing IL approaches have the drawback of expecting extensive demonstration information in long-horizon problems. This paper proposes a novel approach combining IL with different types of RL methods, namely state action reward state action (SARSA) and asynchronous advantage actor-critic (A3C) agents, to overcome the problems of both stand-alone systems. It is addressed how to effectively leverage the teacher feedback, be it direct binary or indirect detailed for the agent learner to learn sequential decision-making policies. The results of this study on various OpenAI Gym environments show that this algorithmic method can be incorporated with different combinations, significantly decreases both human endeavor and tedious exploration process.