 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumor in Word Embeddings: Cockamamie Gobbledegook for Nincompoops
Feb 11, 2019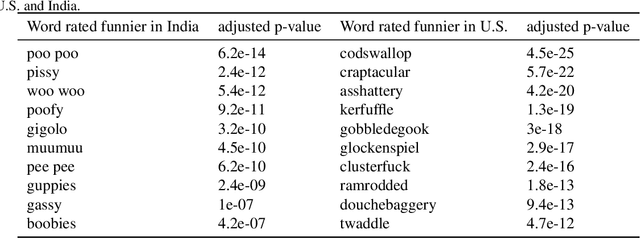
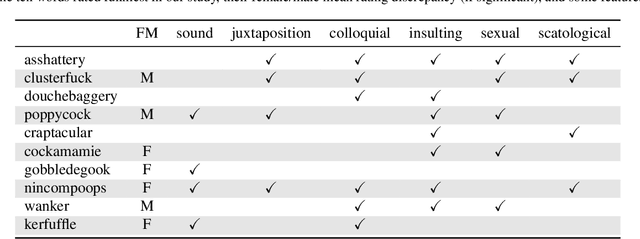

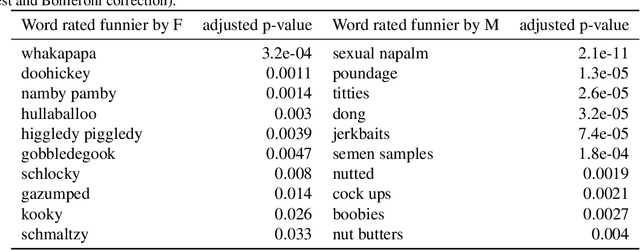
We study humor in Word Embeddings, a popular AI tool that associates each word with a Euclidean vector. We find that: (a) the word vectors capture multiple aspects of humor discussed in theories of humor; and (b) each individual's sense of humor can be represented by a vector, and that these sense-of-humor vectors accurately predict differences in people's sense of humor on new, unrated, words. The fact that single-word humor seems to be relatively easy for AI has implications for the study of humor in language. Humor ratings are taken from the work of Englethaler and Hills (2017) as well as our own crowdsourcing study of 120,000 words.
What are the biases in my word embedding?
Dec 22, 2018



This paper presents an algorithm for enumerating biases in word embeddings. The algorithm exposes a large number of offensive associations related to sensitive features such as race and gender on publicly available embeddings, including a supposedly "debiased" embedding. These embedded biases are concerning in light of the widespread use of word embeddings. The associations are identified by geometric patterns in word embeddings that run parallel between people's names and common lower-case words and phrases. The algorithm is highly unsupervised: it does not even require the sensitive groups (such as gender or race) to be pre-specified. This is desirable because it may not always be easy to identify all vulnerable groups a priori, and because it makes it easier to identify biases against intersectional groups, which depend on combinations of sensitive features. The inputs to our algorithm are a list of target tokens, e.g. names, and a word embedding, and the outputs are a number of Word Embedding Association Tests (WEATs) that capture various biases present in the data. We illustrate the utility of our approach on publicly available word embeddings and lists of names, and evaluate its output using crowdsourcing. We also show how removing names may not remove potential proxy bias.