 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Population-based Search with Active Inference
Aug 18, 2024

The Active Inference framework models perception and action as a unified process, where agents use probabilistic models to predict and actively minimize sensory discrepancies. In complement and contrast, traditional population-based metaheuristics rely on reactive environmental interactions without anticipatory adaptation. This paper proposes the integration of Active Inference into these metaheuristics to enhance performance through anticipatory environmental adaptation. We demonstrate this approach specifically with Ant Colony Optimization (ACO) on the Travelling Salesman Problem (TSP). Experimental results indicate that Active Inference can yield some improved solutions with only a marginal increase in computational cost, with interesting patterns of performance that relate to number and topology of nodes in the graph. Further work will characterize where and when different types of Active Inference augmentation of population metaheuristics may be efficacious.
A Blockchain Protocol for Human-in-the-Loop AI
Nov 20, 2022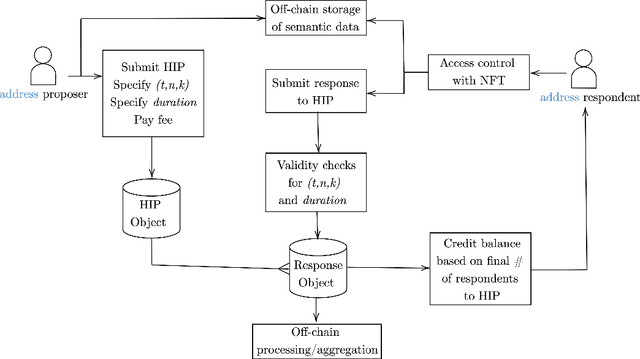

Intelligent human inputs are required both in the training and operation of AI systems, and within the governance of blockchain systems and decentralized autonomous organizations (DAOs). This paper presents a formal definition of Human Intelligence Primitives (HIPs), and describes the design and implementation of an Ethereum protocol for their on-chain collection, modeling, and integration in machine learning workflows.
Predicting Seminal Quality with the Dominance-Based Rough Sets Approach
Dec 24, 2020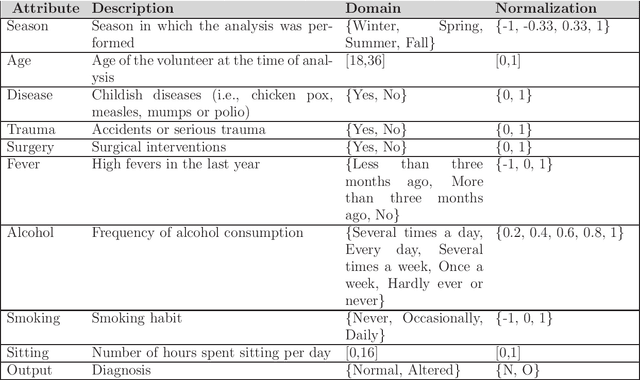



The paper relies on the clinical data of a previously published study. We identify two very questionable assumptions of said work, namely confusing evidence of absence and absence of evidence, and neglecting the ordinal nature of attributes' domains. We then show that using an adequate ordinal methodology such as the dominance-based rough sets approach (DRSA) can significantly improve the predictive accuracy of the expert system, resulting in almost complete accuracy for a dataset of 100 instances. Beyond the performance of DRSA in solving the diagnosis problem at hand, these results suggest the inadequacy and triviality of the underlying dataset. We provide links to open data from the UCI machine learning repository to allow for an easy verification/refutation of the claims made in this paper.
Devolutionary genetic algorithms with application to the minimum labeling Steiner tree problem
Apr 18, 2020This paper characterizes and discusses devolutionary genetic algorithms and evaluates their performances in solving the minimum labeling Steiner tree (MLST) problem. We define devolutionary algorithms as the process of reaching a feasible solution by devolving a population of super-optimal unfeasible solutions over time. We claim that distinguishing them from the widely used evolutionary algorithms is relevant. The most important distinction lies in the fact that in the former type of processes, the value function decreases over successive generation of solutions, thus providing a natural stopping condition for the computation process. We show how classical evolutionary concepts, such as crossing, mutation and fitness can be adapted to aim at reaching an optimal or close-to-optimal solution among the first generations of feasible solutions. We additionally introduce a novel integer linear programming formulation of the MLST problem and a valid constraint used for speeding up the devolutionary process. Finally, we conduct an experiment comparing the performances of devolutionary algorithms to those of state of the art approaches used for solving randomly generated instances of the MLST problem. Results of this experiment support the use of devolutionary algorithms for the MLST problem and their development for other NP-hard combinatorial optimization problems.
Accumulator Bet Selection Through Stochastic Diffusion Search
Apr 18, 2020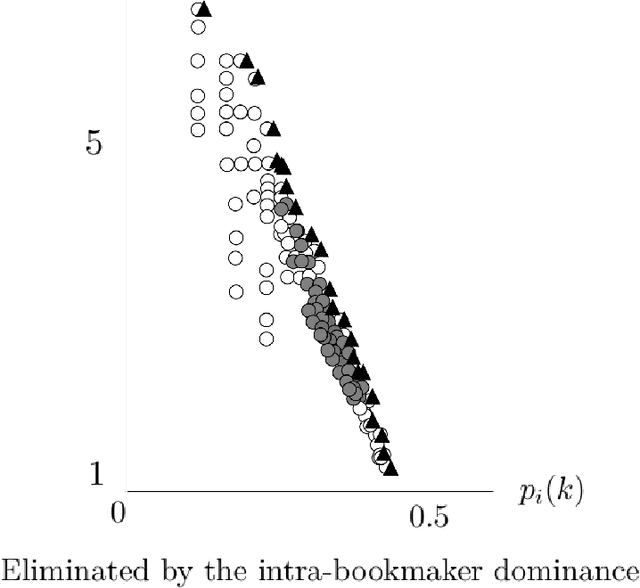

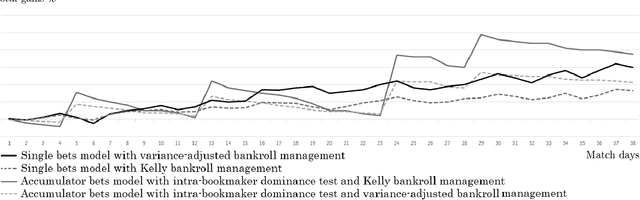

An accumulator is a bet that presents a rather unique payout structure, in that it combines multiple bets into a wager that can generate a total payout given by the multiplication of the individual odds of its parts. These potentially important returns come however at an increased risk of a loss. Indeed, the presence of a single incorrect bet in this selection would make the whole accumulator lose. The complexity of selecting a set of matches to place an accumulator bet on, as well as the number of opportunities to identify winning combinations have both dramatically increased with the easier access to online and offline bookmakers that bettors have nowadays. We address this relatively under-studied combinatorial aspect of sports betting, and propose a binary optimization model for the problem of selecting the most promising combinations of matches, in terms of their total potential payout and probability of a win, to form an accumulator bet. The results of an ongoing computational experiment, in which our model is applied to real data pertaining to the four main football leagues in the world over a complete season, are presented and compared to those of single bet selection methods.
On Evaluating the Quality of Rule-Based Classification Systems
Apr 06, 2020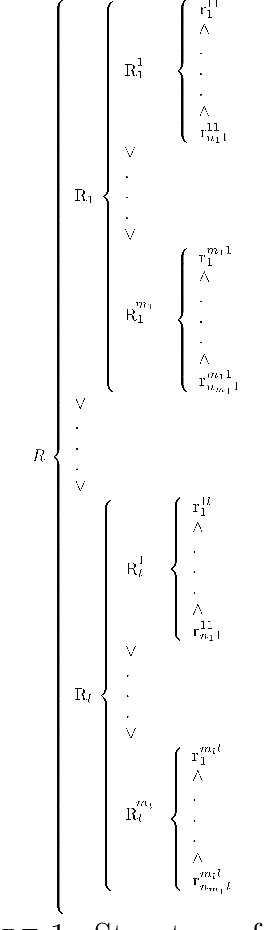



Two indicators are classically used to evaluate the quality of rule-based classification systems: predictive accuracy, i.e. the system's ability to successfully reproduce learning data and coverage, i.e. the proportion of possible cases for which the logical rules constituting the system apply. In this work, we claim that these two indicators may be insufficient, and additional measures of quality may need to be developed. We theoretically show that classification systems presenting "good" predictive accuracy and coverage can, nonetheless, be trivially improved and illustrate this proposition with examples.
* ICIC Express Letters Volume 11, Number 10, October 2017