 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Seminal Quality with the Dominance-Based Rough Sets Approach
Paper and Code
Dec 24, 2020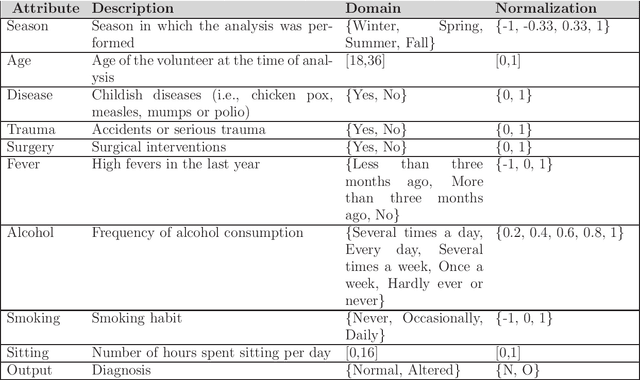



The paper relies on the clinical data of a previously published study. We identify two very questionable assumptions of said work, namely confusing evidence of absence and absence of evidence, and neglecting the ordinal nature of attributes' domains. We then show that using an adequate ordinal methodology such as the dominance-based rough sets approach (DRSA) can significantly improve the predictive accuracy of the expert system, resulting in almost complete accuracy for a dataset of 100 instances. Beyond the performance of DRSA in solving the diagnosis problem at hand, these results suggest the inadequacy and triviality of the underlying dataset. We provide links to open data from the UCI machine learning repository to allow for an easy verification/refutation of the claims made in this paper.