 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient, Exploration-Based Policy Optimisation for Routing Problems
May 31, 2022
Model-free deep-reinforcement-based learning algorithms have been applied to a range of COPs~\cite{bello2016neural}~\cite{kool2018attention}~\cite{nazari2018reinforcement}. However, these approaches suffer from two key challenges when applied to combinatorial problems: insufficient exploration and the requirement of many training examples of the search space to achieve reasonable performance. Combinatorial optimisation can be complex, characterised by search spaces with many optimas and large spaces to search and learn. Therefore, a new method is needed to find good solutions that are more efficient by being more sample efficient. This paper presents a new reinforcement learning approach that is based on entropy. In addition, we design an off-policy-based reinforcement learning technique that maximises the expected return and improves the sample efficiency to achieve faster learning during training time. We systematically evaluate our approach on a range of route optimisation tasks typically used to evaluate learning-based optimisation, such as the such as the Travelling Salesman problems (TSP), Capacitated Vehicle Routing Problem (CVRP). In this paper, we show that our model can generalise to various route problems, such as the split-delivery VRP (SDVRP), and compare the performance of our method with that of current state-of-the-art approaches. The Empirical results show that the proposed method can improve on state-of-the-art methods in terms of solution quality and computation time and generalise to problems of different sizes.
Learning Enhanced Optimisation for Routing Problems
Sep 17, 2021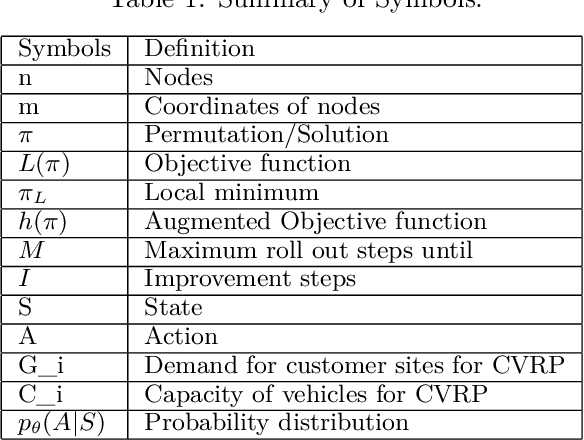
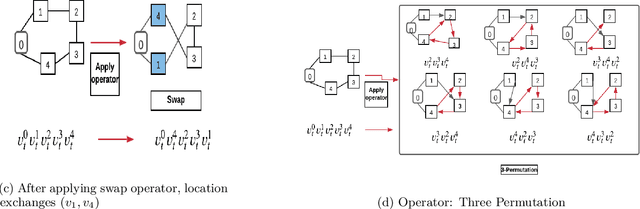
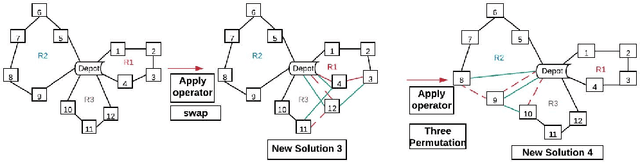
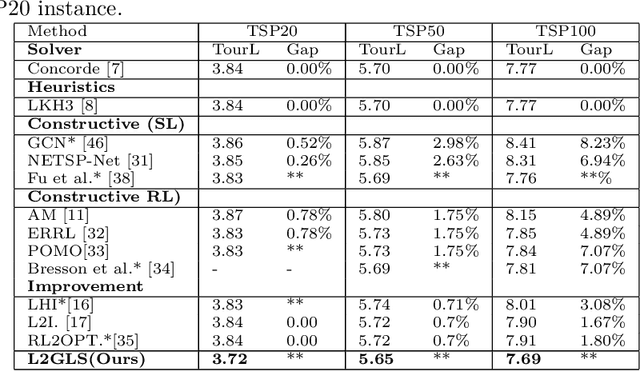
Deep learning approaches have shown promising results in solving routing problems. However, there is still a substantial gap in solution quality between machine learning and operations research algorithms. Recently, another line of research has been introduced that fuses the strengths of machine learning and operational research algorithms. In particular, search perturbation operators have been used to improve the solution. Nevertheless, using the perturbation may not guarantee a quality solution. This paper presents "Learning to Guide Local Search" (L2GLS), a learning-based approach for routing problems that uses a penalty term and reinforcement learning to adaptively adjust search efforts. L2GLS combines local search (LS) operators' strengths with penalty terms to escape local optimals. Routing problems have many practical applications, often presetting larger instances that are still challenging for many existing algorithms introduced in the learning to optimise field. We show that L2GLS achieves the new state-of-the-art results on larger TSP and CVRP over other machine learning methods.
Learning Vehicle Routing Problems using Policy Optimisation
Dec 24, 2020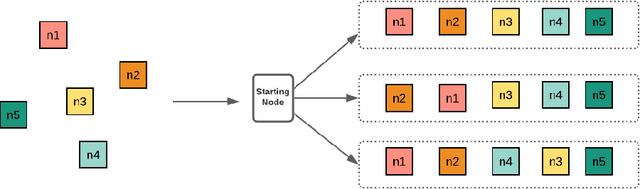
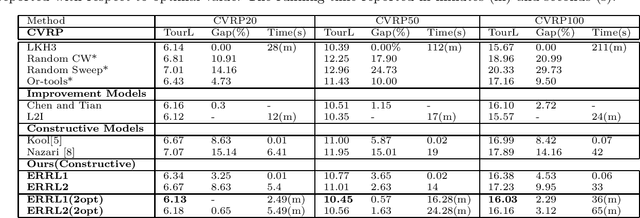
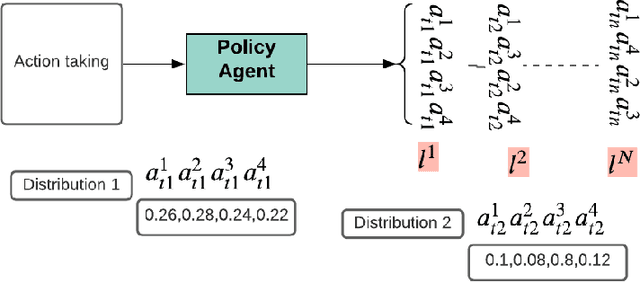
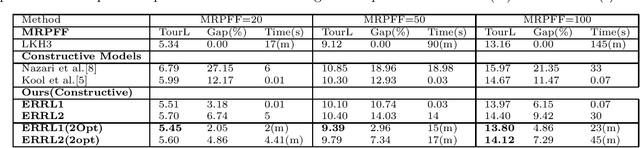
Deep reinforcement learning (DRL) has been used to learn effective heuristics for solving complex combinatorial optimisation problem via policy networks and have demonstrated promising performance. Existing works have focused on solving (vehicle) routing problems as they have a nice balance between non-triviality and difficulty. State-of-the-art approaches learn a policy using reinforcement learning, and the learnt policy acts as a pseudo solver. These approaches have demonstrated good performance in some cases, but given the large search space typical combinatorial/routing problem, they can converge too quickly to poor policy. To prevent this, in this paper, we propose an approach name entropy regularised reinforcement learning (ERRL) that supports exploration by providing more stochastic policies, which tends to improve optimisation. Empirically, the low variance ERRL offers RL training fast and stable. We also introduce a combination of local search operators during test time, which significantly improves solution and complement ERRL. We qualitatively demonstrate that for vehicle routing problems, a policy with higher entropy can make the optimisation landscape smooth which makes it easier to optimise. The quantitative evaluation shows that the performance of the model is comparable with the state-of-the-art variants. In our evaluation, we experimentally illustrate that the model produces state-of-the-art performance on variants of Vehicle Routing problems such as Capacitated Vehicle Routing Problem (CVRP), Multiple Routing with Fixed Fleet Problems (MRPFF) and Travelling Salesman problem.
Learning to Optimise General TSP Instances
Nov 03, 2020
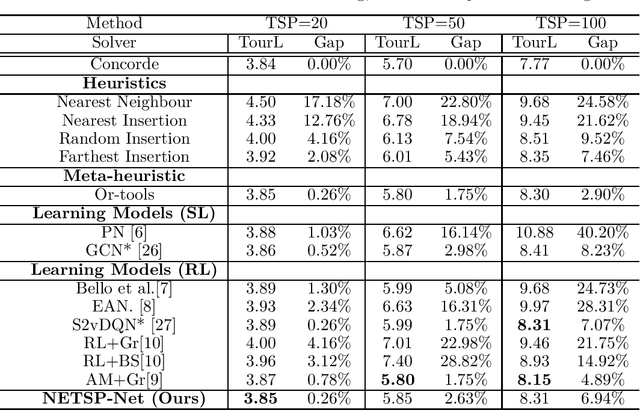
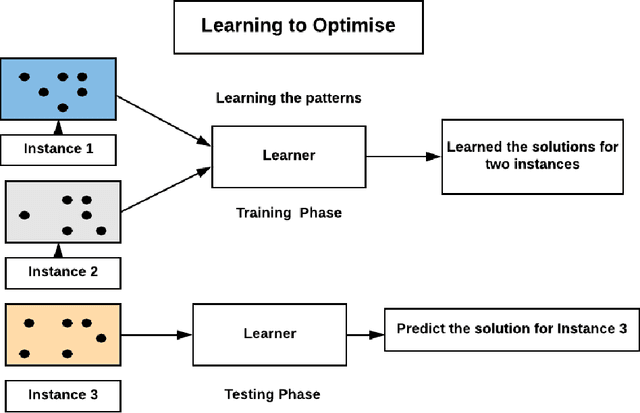
The Travelling Salesman Problem (TSP) is a classical combinatorial optimisation problem. Deep learning has been successfully extended to meta-learning, where previous solving efforts assist in learning how to optimise future optimisation instances. In recent years, learning to optimise approaches have shown success in solving TSP problems. However, they focus on one type of TSP problem, namely ones where the points are uniformly distributed in Euclidean spaces and have issues in generalising to other embedding spaces, e.g., spherical distance spaces, and to TSP instances where the points are distributed in a non-uniform manner. An aim of learning to optimise is to train once and solve across a broad spectrum of (TSP) problems. Although supervised learning approaches have shown to achieve more optimal solutions than unsupervised approaches, they do require the generation of training data and running a solver to obtain solutions to learn from, which can be time-consuming and difficult to find reasonable solutions for harder TSP instances. Hence this paper introduces a new learning-based approach to solve a variety of different and common TSP problems that are trained on easier instances which are faster to train and are easier to obtain better solutions. We name this approach the non-Euclidean TSP network (NETSP-Net). The approach is evaluated on various TSP instances using the benchmark TSPLIB dataset and popular instance generator used in the literature. We performed extensive experiments that indicate our approach generalises across many types of instances and scales to instances that are larger than what was used during training.