 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient, Exploration-Based Policy Optimisation for Routing Problems
Paper and Code
May 31, 2022
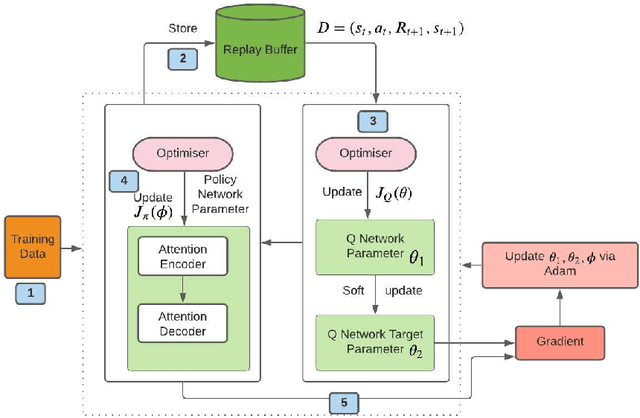
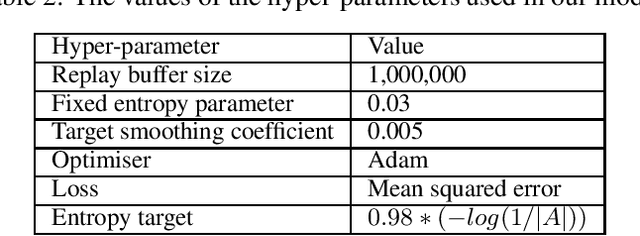
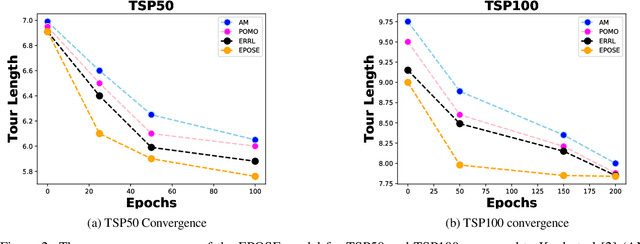
Model-free deep-reinforcement-based learning algorithms have been applied to a range of COPs~\cite{bello2016neural}~\cite{kool2018attention}~\cite{nazari2018reinforcement}. However, these approaches suffer from two key challenges when applied to combinatorial problems: insufficient exploration and the requirement of many training examples of the search space to achieve reasonable performance. Combinatorial optimisation can be complex, characterised by search spaces with many optimas and large spaces to search and learn. Therefore, a new method is needed to find good solutions that are more efficient by being more sample efficient. This paper presents a new reinforcement learning approach that is based on entropy. In addition, we design an off-policy-based reinforcement learning technique that maximises the expected return and improves the sample efficiency to achieve faster learning during training time. We systematically evaluate our approach on a range of route optimisation tasks typically used to evaluate learning-based optimisation, such as the such as the Travelling Salesman problems (TSP), Capacitated Vehicle Routing Problem (CVRP). In this paper, we show that our model can generalise to various route problems, such as the split-delivery VRP (SDVRP), and compare the performance of our method with that of current state-of-the-art approaches. The Empirical results show that the proposed method can improve on state-of-the-art methods in terms of solution quality and computation time and generalise to problems of different sizes.