 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Vehicle Routing Problems using Policy Optimisation
Paper and Code
Dec 24, 2020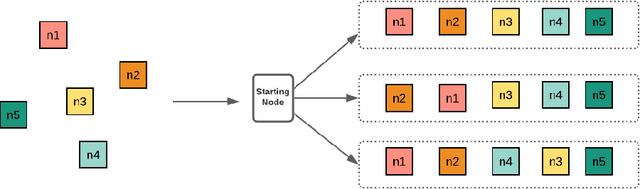
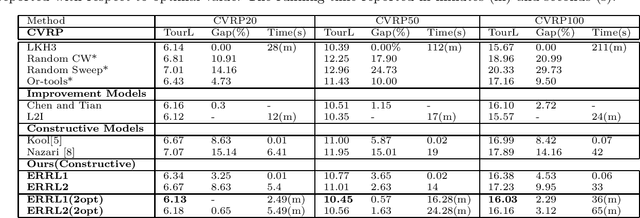
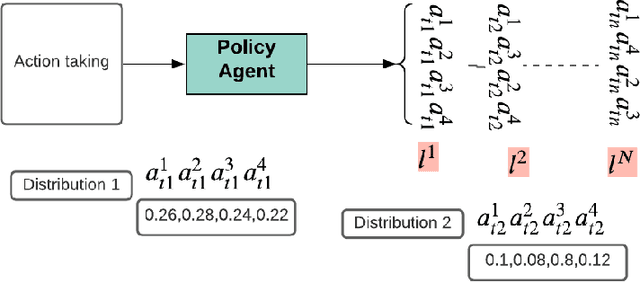
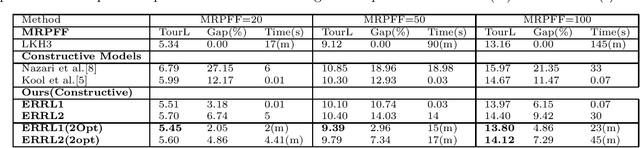
Deep reinforcement learning (DRL) has been used to learn effective heuristics for solving complex combinatorial optimisation problem via policy networks and have demonstrated promising performance. Existing works have focused on solving (vehicle) routing problems as they have a nice balance between non-triviality and difficulty. State-of-the-art approaches learn a policy using reinforcement learning, and the learnt policy acts as a pseudo solver. These approaches have demonstrated good performance in some cases, but given the large search space typical combinatorial/routing problem, they can converge too quickly to poor policy. To prevent this, in this paper, we propose an approach name entropy regularised reinforcement learning (ERRL) that supports exploration by providing more stochastic policies, which tends to improve optimisation. Empirically, the low variance ERRL offers RL training fast and stable. We also introduce a combination of local search operators during test time, which significantly improves solution and complement ERRL. We qualitatively demonstrate that for vehicle routing problems, a policy with higher entropy can make the optimisation landscape smooth which makes it easier to optimise. The quantitative evaluation shows that the performance of the model is comparable with the state-of-the-art variants. In our evaluation, we experimentally illustrate that the model produces state-of-the-art performance on variants of Vehicle Routing problems such as Capacitated Vehicle Routing Problem (CVRP), Multiple Routing with Fixed Fleet Problems (MRPFF) and Travelling Salesman problem.