 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-task Learning Approach for Named Entity Recognition using Local Detection
Apr 21, 2019

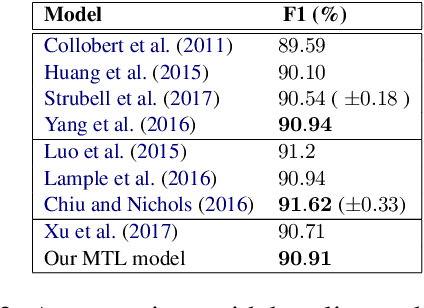

Named entity recognition (NER) systems that perform well require task-related and manually annotated datasets. However, they are expensive to develop, and are thus limited in size. As there already exists a large number of NER datasets that share a certain degree of relationship but differ in content, it is important to explore the question of whether such datasets can be combined as a simple method for improving NER performance. To investigate this, we developed a novel locally detecting multitask model using FFNNs. The model relies on encoding variable-length sequences of words into theoretically lossless and unique fixed-size representations. We applied this method to several well-known NER tasks and compared the results of our model to baseline models as well as other published results. As a result, we observed competitive performance in nearly all of the tasks.
Effective Context and Fragment Feature Usage for Named Entity Recognition
Apr 21, 2019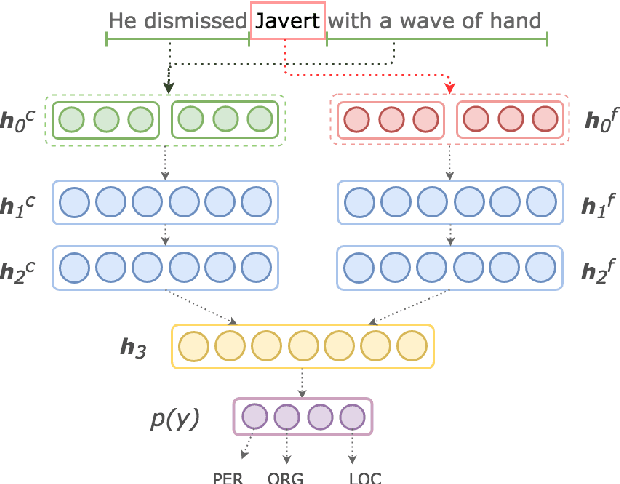


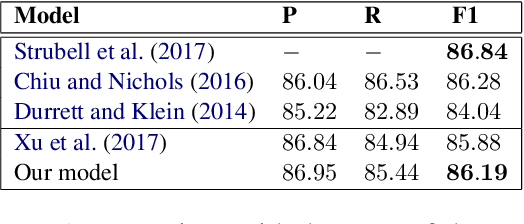
In this paper, we explore a new approach to named entity recognition (NER) with the goal of learning from context and fragment features more effectively, contributing to the improvement of overall recognition performance. We use the recent fixed-size ordinally forgetting encoding (FOFE) method to fully encode each sentence fragment and its left-right contexts into a fixed-size representation. Next, we organize the context and fragment features into groups, and feed each feature group to dedicated fully-connected layers. Finally, we merge each group's final dedicated layers and add a shared layer leading to a single output. The outcome of our experiments show that, given only tokenized text and trained word embeddings, our system outperforms our baseline models, and is competitive to the state-of-the-arts of various well-known NER tasks.