 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-task Learning Approach for Named Entity Recognition using Local Detection
Paper and Code


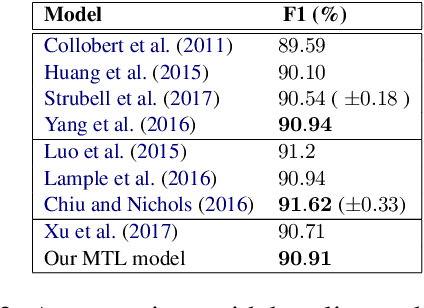

Named entity recognition (NER) systems that perform well require task-related and manually annotated datasets. However, they are expensive to develop, and are thus limited in size. As there already exists a large number of NER datasets that share a certain degree of relationship but differ in content, it is important to explore the question of whether such datasets can be combined as a simple method for improving NER performance. To investigate this, we developed a novel locally detecting multitask model using FFNNs. The model relies on encoding variable-length sequences of words into theoretically lossless and unique fixed-size representations. We applied this method to several well-known NER tasks and compared the results of our model to baseline models as well as other published results. As a result, we observed competitive performance in nearly all of the tasks.