 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Randomized Ensembles to Adversarial Perturbations
Feb 06, 2023



Randomized ensemble classifiers (RECs), where one classifier is randomly selected during inference, have emerged as an attractive alternative to traditional ensembling methods for realizing adversarially robust classifiers with limited compute requirements. However, recent works have shown that existing methods for constructing RECs are more vulnerable than initially claimed, casting major doubts on their efficacy and prompting fundamental questions such as: "When are RECs useful?", "What are their limits?", and "How do we train them?". In this work, we first demystify RECs as we derive fundamental results regarding their theoretical limits, necessary and sufficient conditions for them to be useful, and more. Leveraging this new understanding, we propose a new boosting algorithm (BARRE) for training robust RECs, and empirically demonstrate its effectiveness at defending against strong $\ell_\infty$ norm-bounded adversaries across various network architectures and datasets.
Adversarial Vulnerability of Randomized Ensembles
Jun 14, 2022
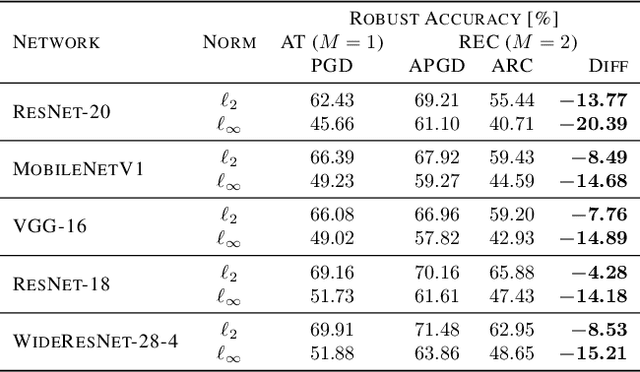
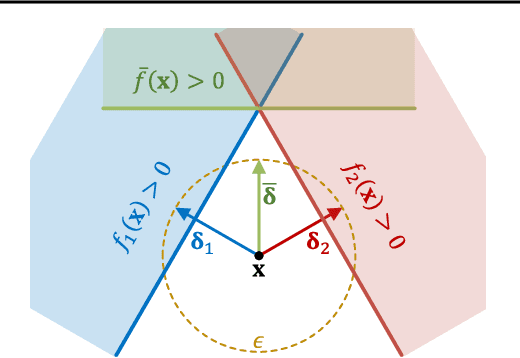
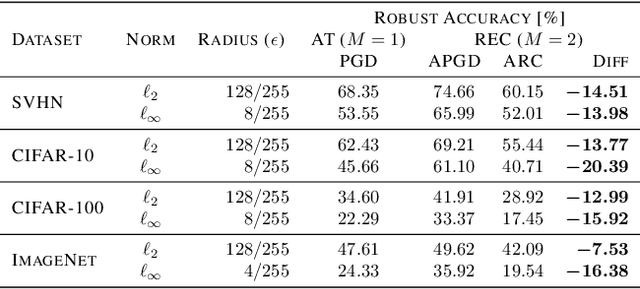
Despite the tremendous success of deep neural networks across various tasks, their vulnerability to imperceptible adversarial perturbations has hindered their deployment in the real world. Recently, works on randomized ensembles have empirically demonstrated significant improvements in adversarial robustness over standard adversarially trained (AT) models with minimal computational overhead, making them a promising solution for safety-critical resource-constrained applications. However, this impressive performance raises the question: Are these robustness gains provided by randomized ensembles real? In this work we address this question both theoretically and empirically. We first establish theoretically that commonly employed robustness evaluation methods such as adaptive PGD provide a false sense of security in this setting. Subsequently, we propose a theoretically-sound and efficient adversarial attack algorithm (ARC) capable of compromising random ensembles even in cases where adaptive PGD fails to do so. We conduct comprehensive experiments across a variety of network architectures, training schemes, datasets, and norms to support our claims, and empirically establish that randomized ensembles are in fact more vulnerable to $\ell_p$-bounded adversarial perturbations than even standard AT models. Our code can be found at https://github.com/hsndbk4/ARC.
Generalized Depthwise-Separable Convolutions for Adversarially Robust and Efficient Neural Networks
Nov 06, 2021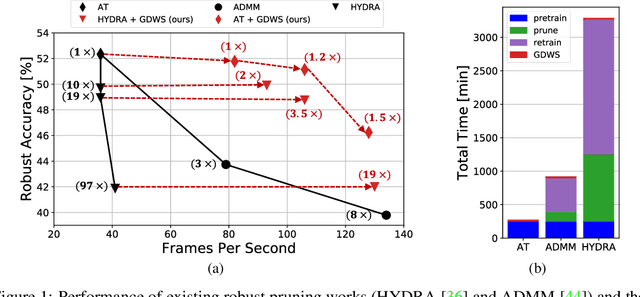

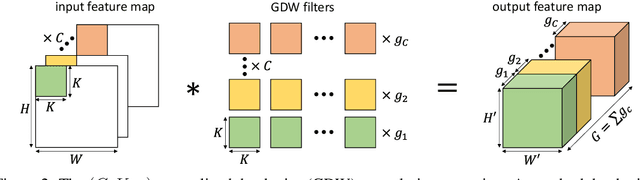
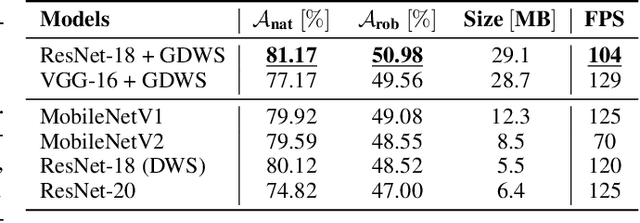
Despite their tremendous successes, convolutional neural networks (CNNs) incur high computational/storage costs and are vulnerable to adversarial perturbations. Recent works on robust model compression address these challenges by combining model compression techniques with adversarial training. But these methods are unable to improve throughput (frames-per-second) on real-life hardware while simultaneously preserving robustness to adversarial perturbations. To overcome this problem, we propose the method of Generalized Depthwise-Separable (GDWS) convolution -- an efficient, universal, post-training approximation of a standard 2D convolution. GDWS dramatically improves the throughput of a standard pre-trained network on real-life hardware while preserving its robustness. Lastly, GDWS is scalable to large problem sizes since it operates on pre-trained models and doesn't require any additional training. We establish the optimality of GDWS as a 2D convolution approximator and present exact algorithms for constructing optimal GDWS convolutions under complexity and error constraints. We demonstrate the effectiveness of GDWS via extensive experiments on CIFAR-10, SVHN, and ImageNet datasets. Our code can be found at https://github.com/hsndbk4/GDWS.
Robustifying $\ell_\infty$ Adversarial Training to the Union of Perturbation Models
Jun 11, 2021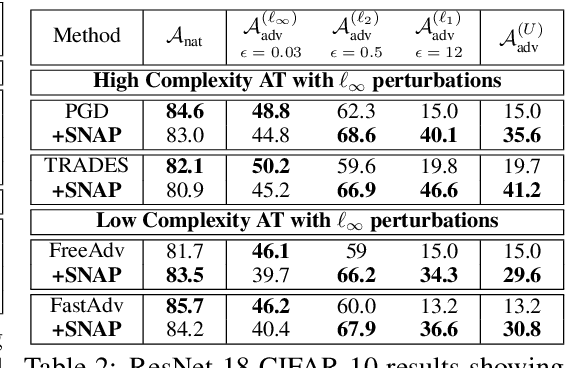
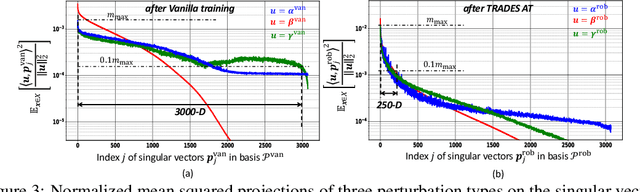
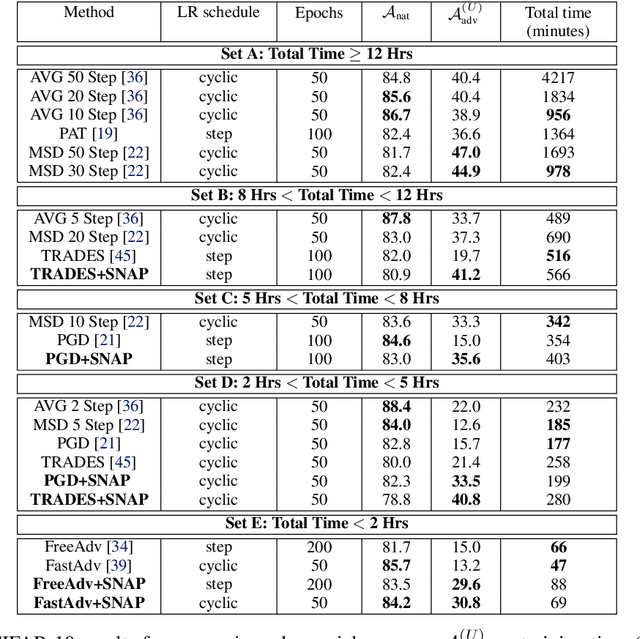
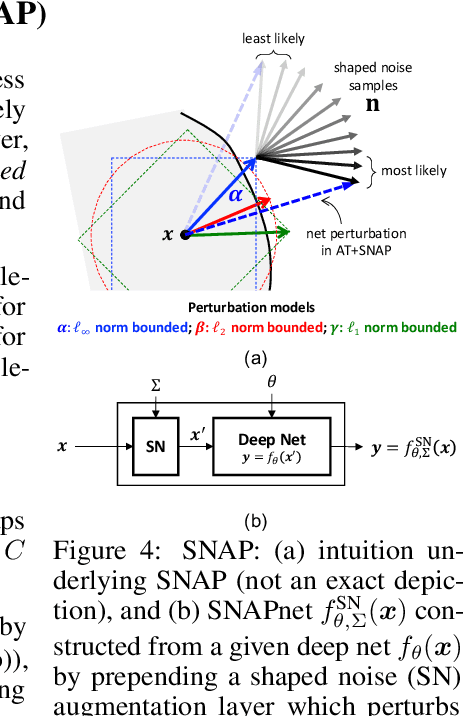
Classical adversarial training (AT) frameworks are designed to achieve high adversarial accuracy against a single attack type, typically $\ell_\infty$ norm-bounded perturbations. Recent extensions in AT have focused on defending against the union of multiple perturbations but this benefit is obtained at the expense of a significant (up to $10\times$) increase in training complexity over single-attack $\ell_\infty$ AT. In this work, we expand the capabilities of widely popular single-attack $\ell_\infty$ AT frameworks to provide robustness to the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations while preserving their training efficiency. Our technique, referred to as Shaped Noise Augmented Processing (SNAP), exploits a well-established byproduct of single-attack AT frameworks -- the reduction in the curvature of the decision boundary of networks. SNAP prepends a given deep net with a shaped noise augmentation layer whose distribution is learned along with network parameters using any standard single-attack AT. As a result, SNAP enhances adversarial accuracy of ResNet-18 on CIFAR-10 against the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations by 14%-to-20% for four state-of-the-art (SOTA) single-attack $\ell_\infty$ AT frameworks, and, for the first time, establishes a benchmark for ResNet-50 and ResNet-101 on ImageNet.
Fundamental Limits on Energy-Delay-Accuracy of In-memory Architectures in Inference Applications
Dec 25, 2020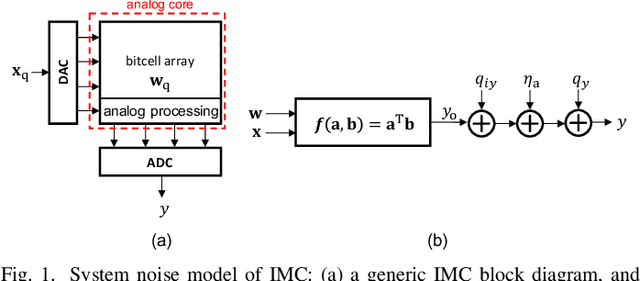
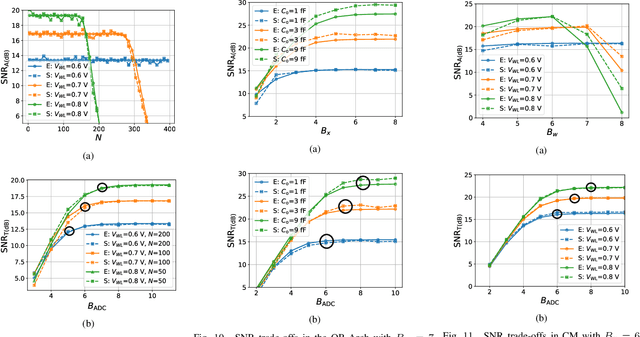

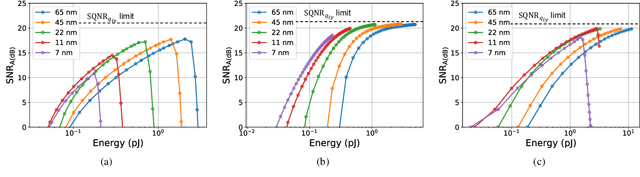
This paper obtains fundamental limits on the computational precision of in-memory computing architectures (IMCs). An IMC noise model and associated SNR metrics are defined and their interrelationships analyzed to show that the accuracy of IMCs is fundamentally limited by the compute SNR ($\text{SNR}_{\text{a}}$) of its analog core, and that activation, weight and output precision needs to be assigned appropriately for the final output SNR $\text{SNR}_{\text{T}} \rightarrow \text{SNR}_{\text{a}}$. The minimum precision criterion (MPC) is proposed to minimize the ADC precision. Three in-memory compute models - charge summing (QS), current summing (IS) and charge redistribution (QR) - are shown to underlie most known IMCs. Noise, energy and delay expressions for the compute models are developed and employed to derive expressions for the SNR, ADC precision, energy, and latency of IMCs. The compute SNR expressions are validated via Monte Carlo simulations in a 65 nm CMOS process. For a 512 row SRAM array, it is shown that: 1) IMCs have an upper bound on their maximum achievable $\text{SNR}_{\text{a}}$ due to constraints on energy, area and voltage swing, and this upper bound reduces with technology scaling for QS-based architectures; 2) MPC enables $\text{SNR}_{\text{T}} \rightarrow \text{SNR}_{\text{a}}$ to be realized with minimal ADC precision; 3) QS-based (QR-based) architectures are preferred for low (high) compute SNR scenarios.
Energy-efficient Machine Learning in Silicon: A Communications-inspired Approach
Oct 25, 2016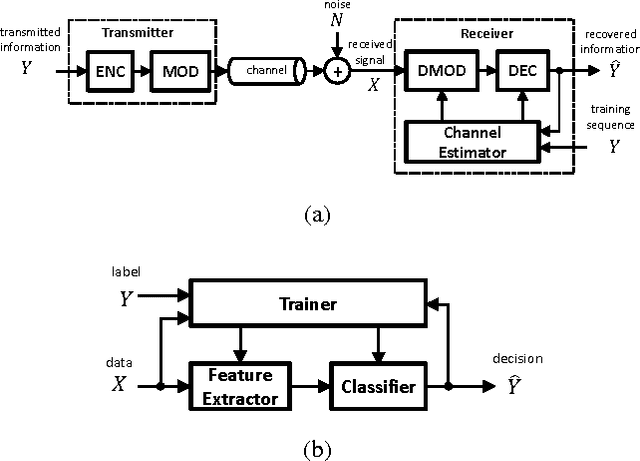
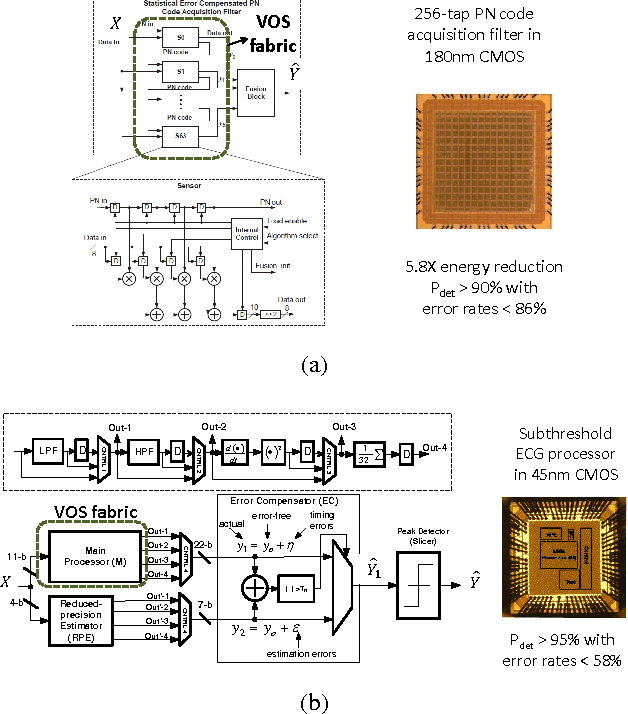
This position paper advocates a communications-inspired approach to the design of machine learning systems on energy-constrained embedded `always-on' platforms. The communications-inspired approach has two versions - 1) a deterministic version where existing low-power communication IC design methods are repurposed, and 2) a stochastic version referred to as Shannon-inspired statistical information processing employing information-based metrics, statistical error compensation (SEC), and retraining-based methods to implement ML systems on stochastic circuit/device fabrics operating at the limits of energy-efficiency. The communications-inspired approach has the potential to fully leverage the opportunities afforded by ML algorithms and applications in order to address the challenges inherent in their deployment on energy-constrained platforms.