 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA phonetic model of non-native spoken word processing
Jan 27, 2021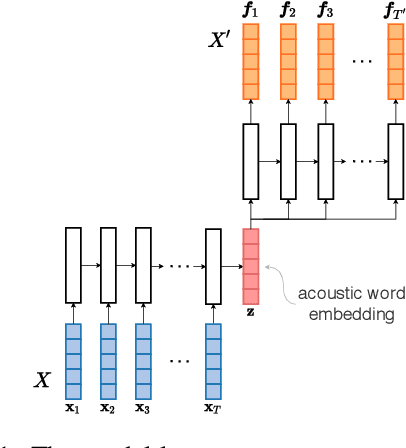

Non-native speakers show difficulties with spoken word processing. Many studies attribute these difficulties to imprecise phonological encoding of words in the lexical memory. We test an alternative hypothesis: that some of these difficulties can arise from the non-native speakers' phonetic perception. We train a computational model of phonetic learning, which has no access to phonology, on either one or two languages. We first show that the model exhibits predictable behaviors on phone-level and word-level discrimination tasks. We then test the model on a spoken word processing task, showing that phonology may not be necessary to explain some of the word processing effects observed in non-native speakers. We run an additional analysis of the model's lexical representation space, showing that the two training languages are not fully separated in that space, similarly to the languages of a bilingual human speaker.
Evaluating computational models of infant phonetic learning across languages
Aug 06, 2020



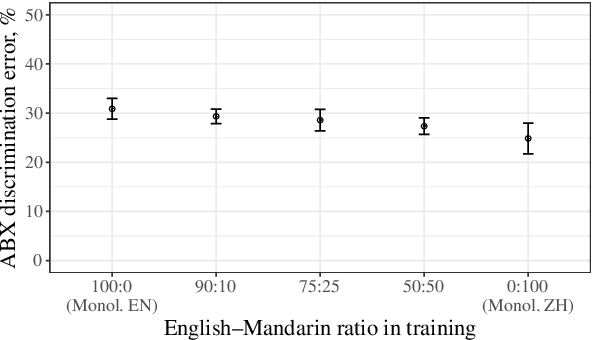
In the first year of life, infants' speech perception becomes attuned to the sounds of their native language. Many accounts of this early phonetic learning exist, but computational models predicting the attunement patterns observed in infants from the speech input they hear have been lacking. A recent study presented the first such model, drawing on algorithms proposed for unsupervised learning from naturalistic speech, and tested it on a single phone contrast. Here we study five such algorithms, selected for their potential cognitive relevance. We simulate phonetic learning with each algorithm and perform tests on three phone contrasts from different languages, comparing the results to infants' discrimination patterns. The five models display varying degrees of agreement with empirical observations, showing that our approach can help decide between candidate mechanisms for early phonetic learning, and providing insight into which aspects of the models are critical for capturing infants' perceptual development.
* 7 pages, 1 figure
Infant directed speech is consistent with teaching
Jun 01, 2016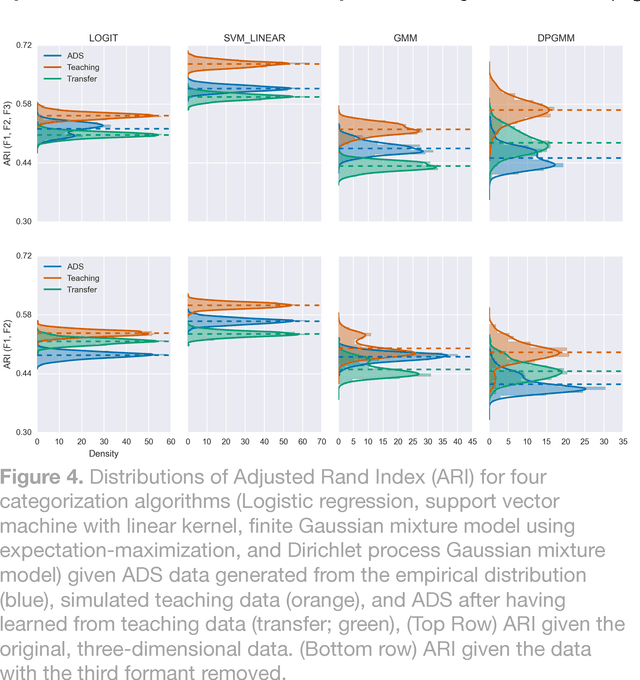
Infant-directed speech (IDS) has distinctive properties that differ from adult-directed speech (ADS). Why it has these properties -- and whether they are intended to facilitate language learning -- is matter of contention. We argue that much of this disagreement stems from lack of a formal, guiding theory of how phonetic categories should best be taught to infant-like learners. In the absence of such a theory, researchers have relied on intuitions about learning to guide the argument. We use a formal theory of teaching, validated through experiments in other domains, as the basis for a detailed analysis of whether IDS is well-designed for teaching phonetic categories. Using the theory, we generate ideal data for teaching phonetic categories in English. We qualitatively compare the simulated teaching data with human IDS, finding that the teaching data exhibit many features of IDS, including some that have been taken as evidence IDS is not for teaching. The simulated data reveal potential pitfalls for experimentalists exploring the role of IDS in language learning. Focusing on different formants and phoneme sets leads to different conclusions, and the benefit of the teaching data to learners is not apparent until a sufficient number of examples have been provided. Finally, we investigate transfer of IDS to learning ADS. The teaching data improves classification of ADS data, but only for the learner they were generated to teach; not universally across all classes of learner. This research offers a theoretically-grounded framework that empowers experimentalists to systematically evaluate whether IDS is for teaching.