 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing On Targets For Improving Weakly Supervised Visual Grounding
Feb 22, 2023Weakly supervised visual grounding aims to predict the region in an image that corresponds to a specific linguistic query, where the mapping between the target object and query is unknown in the training stage. The state-of-the-art method uses a vision language pre-training model to acquire heatmaps from Grad-CAM, which matches every query word with an image region, and uses the combined heatmap to rank the region proposals. In this paper, we propose two simple but efficient methods for improving this approach. First, we propose a target-aware cropping approach to encourage the model to learn both object and scene level semantic representations. Second, we apply dependency parsing to extract words related to the target object, and then put emphasis on these words in the heatmap combination. Our method surpasses the previous SOTA methods on RefCOCO, RefCOCO+, and RefCOCOg by a notable margin.
Physical Cue based Depth-Sensing by Color Coding with Deaberration Network
Aug 01, 2019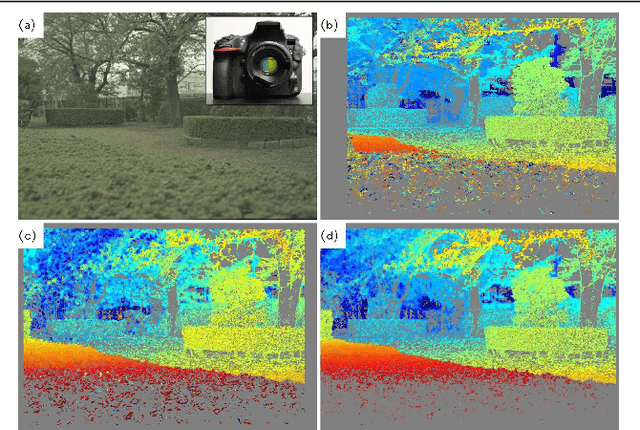
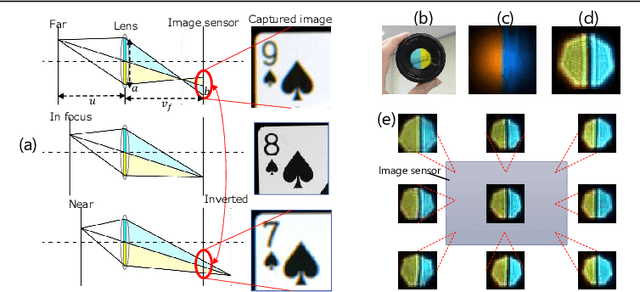
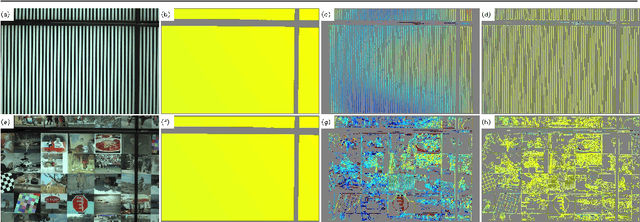
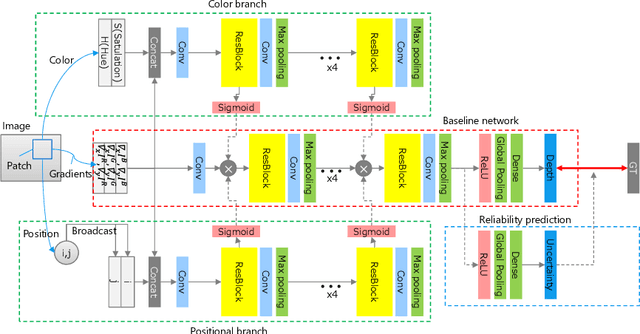
Color-coded aperture (CCA) methods can physically measure the depth of a scene given by physical cues from a single-shot image of a monocular camera. However, they are vulnerable to actual lens aberrations in real scenes because they assume an ideal lens for simplifying algorithms. In this paper, we propose physical cue-based deep learning for CCA photography. To address actual lens aberrations, we developed a deep deaberration network (DDN) that is additionally equipped with a self-attention mechanism of position and color channels to efficiently learn the lens aberration. Furthermore, a new Bayes L1 loss function based on Bayesian deep learning enables to handle the uncertainty of depth estimation more accurately. Quantitative and qualitative comparisons demonstrate that our method is superior to conventional methods including real outdoor scenes. Furthermore, compared to a long-baseline stereo camera, the proposed method provides an error-free depth map at close range, as there is no blind spot between the left and right cameras.