 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing On Targets For Improving Weakly Supervised Visual Grounding
Feb 22, 2023Weakly supervised visual grounding aims to predict the region in an image that corresponds to a specific linguistic query, where the mapping between the target object and query is unknown in the training stage. The state-of-the-art method uses a vision language pre-training model to acquire heatmaps from Grad-CAM, which matches every query word with an image region, and uses the combined heatmap to rank the region proposals. In this paper, we propose two simple but efficient methods for improving this approach. First, we propose a target-aware cropping approach to encourage the model to learn both object and scene level semantic representations. Second, we apply dependency parsing to extract words related to the target object, and then put emphasis on these words in the heatmap combination. Our method surpasses the previous SOTA methods on RefCOCO, RefCOCO+, and RefCOCOg by a notable margin.
BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks
Jul 18, 2017
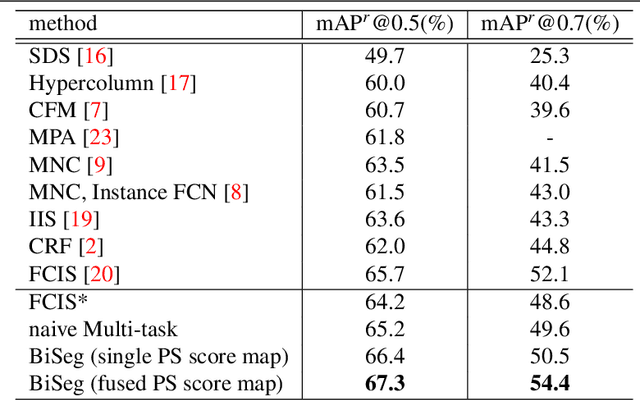
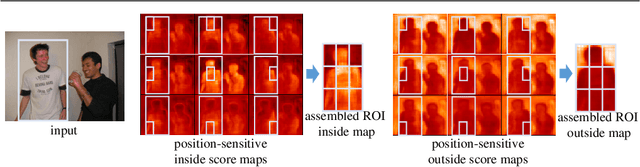
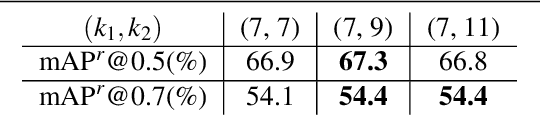
We present a simple and effective framework for simultaneous semantic segmentation and instance segmentation with Fully Convolutional Networks (FCNs). The method, called BiSeg, predicts instance segmentation as a posterior in Bayesian inference, where semantic segmentation is used as a prior. We extend the idea of position-sensitive score maps used in recent methods to a fusion of multiple score maps at different scales and partition modes, and adopt it as a robust likelihood for instance segmentation inference. As both Bayesian inference and map fusion are performed per pixel, BiSeg is a fully convolutional end-to-end solution that inherits all the advantages of FCNs. We demonstrate state-of-the-art instance segmentation accuracy on PASCAL VOC.