 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEEETs-Dial: Linguistic Entrainment in End-to-End Task-oriented Dialogue systems
Nov 15, 2023

Linguistic entrainment, or alignment, represents a phenomenon where linguistic patterns employed by conversational participants converge to one another. While alignment has been shown to produce a more natural user experience, most dialogue systems do not have any provisions for it. In this work, we introduce methods for achieving dialogue alignment in a GPT-2-based end-to-end dialogue system through the utilization of shared vocabulary. We experiment with training instance weighting, alignment-specific loss, and additional conditioning to generate responses that align with the user. By comparing different entrainment techniques on the MultiWOZ dataset, we demonstrate that all three approaches produce significantly better-aligned results than the baseline, as confirmed by both automated and manual evaluation metrics.
Dict-NMT: Bilingual Dictionary based NMT for Extremely Low Resource Languages
Jun 09, 2022
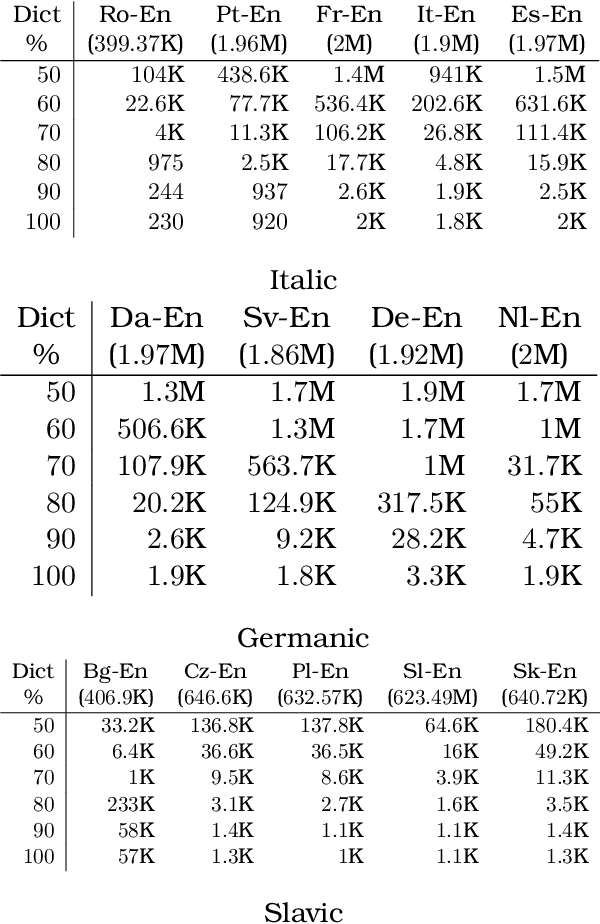
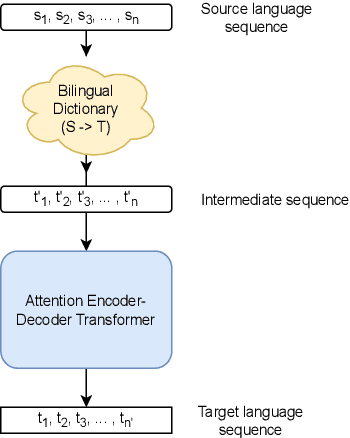
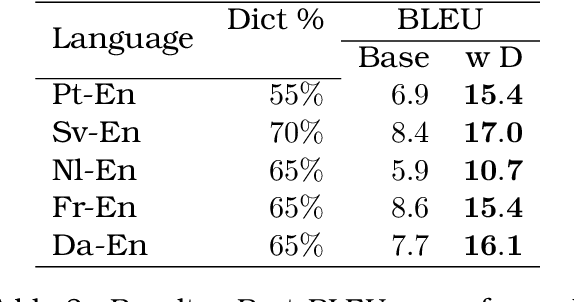
Neural Machine Translation (NMT) models have been effective on large bilingual datasets. However, the existing methods and techniques show that the model's performance is highly dependent on the number of examples in training data. For many languages, having such an amount of corpora is a far-fetched dream. Taking inspiration from monolingual speakers exploring new languages using bilingual dictionaries, we investigate the applicability of bilingual dictionaries for languages with extremely low, or no bilingual corpus. In this paper, we explore methods using bilingual dictionaries with an NMT model to improve translations for extremely low resource languages. We extend this work to multilingual systems, exhibiting zero-shot properties. We present a detailed analysis of the effects of the quality of dictionaries, training dataset size, language family, etc., on the translation quality. Results on multiple low-resource test languages show a clear advantage of our bilingual dictionary-based method over the baselines.
QUARC: Quaternion Multi-Modal Fusion Architecture For Hate Speech Classification
Dec 15, 2020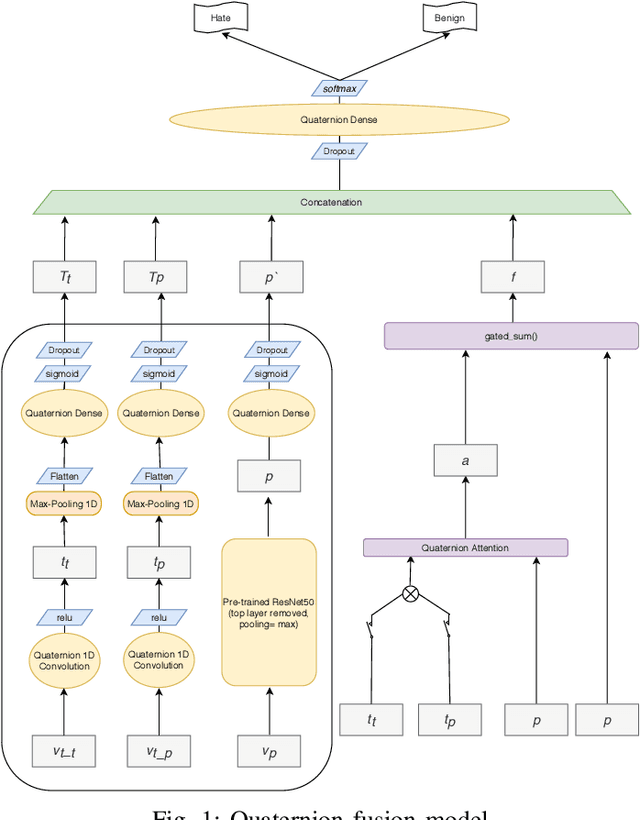

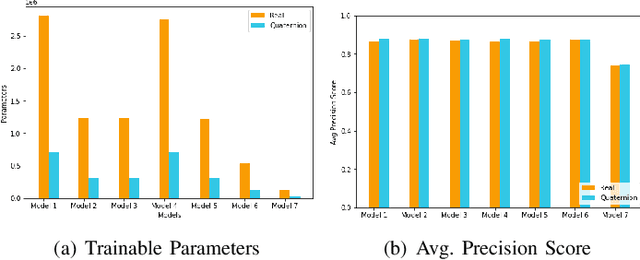
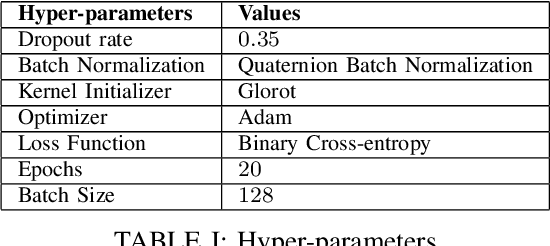
Hate speech, quite common in the age of social media, at times harmless but can also cause mental trauma to someone or even riots in communities. Image of a religious symbol with derogatory comment or video of a man abusing a particular community, all become hate speech with its every modality (such as text, image, and audio) contributing towards it. Models based on a particular modality of hate speech post on social media are not useful, rather, we need models like multi-modal fusion models that consider both image and text while classifying hate speech. Text-image fusion models are heavily parameterized, hence we propose a quaternion neural network-based model having additional fusion components for each pair of modalities. The model is tested on the MMHS150K twitter dataset for hate speech classification. The model shows an almost 75% reduction in parameters and also benefits us in terms of storage space and training time while being at par in terms of performance as compared to its real counterpart.