 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDict-NMT: Bilingual Dictionary based NMT for Extremely Low Resource Languages
Paper and Code
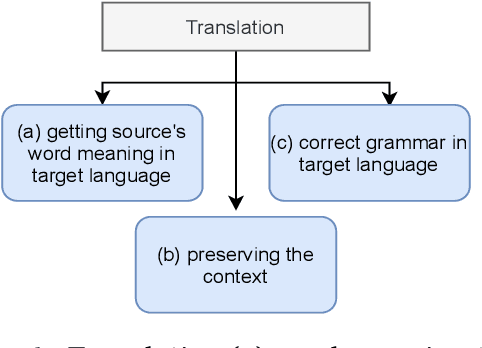
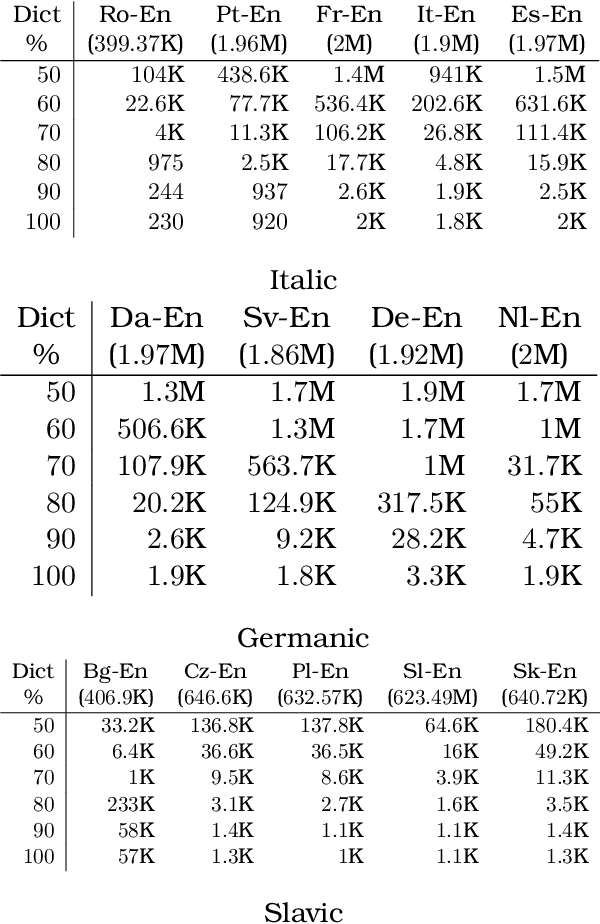
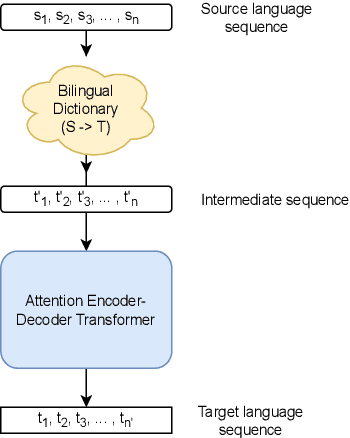
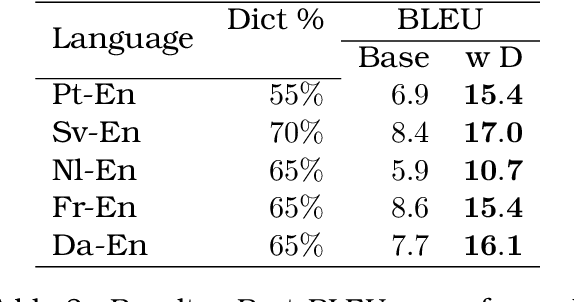
Neural Machine Translation (NMT) models have been effective on large bilingual datasets. However, the existing methods and techniques show that the model's performance is highly dependent on the number of examples in training data. For many languages, having such an amount of corpora is a far-fetched dream. Taking inspiration from monolingual speakers exploring new languages using bilingual dictionaries, we investigate the applicability of bilingual dictionaries for languages with extremely low, or no bilingual corpus. In this paper, we explore methods using bilingual dictionaries with an NMT model to improve translations for extremely low resource languages. We extend this work to multilingual systems, exhibiting zero-shot properties. We present a detailed analysis of the effects of the quality of dictionaries, training dataset size, language family, etc., on the translation quality. Results on multiple low-resource test languages show a clear advantage of our bilingual dictionary-based method over the baselines.