 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Outcome-Driven Patient Subgroups: A Machine Learning Analysis Across Six Depression Treatment Studies
Mar 30, 2023Major depressive disorder (MDD) is a heterogeneous condition; multiple underlying neurobiological substrates could be associated with treatment response variability. Understanding the sources of this variability and predicting outcomes has been elusive. Machine learning has shown promise in predicting treatment response in MDD, but one limitation has been the lack of clinical interpretability of machine learning models. We analyzed data from six clinical trials of pharmacological treatment for depression (total n = 5438) using the Differential Prototypes Neural Network (DPNN), a neural network model that derives patient prototypes which can be used to derive treatment-relevant patient clusters while learning to generate probabilities for differential treatment response. A model classifying remission and outputting individual remission probabilities for five first-line monotherapies and three combination treatments was trained using clinical and demographic data. Model validity and clinical utility were measured based on area under the curve (AUC) and expected improvement in sample remission rate with model-guided treatment, respectively. Post-hoc analyses yielded clusters (subgroups) based on patient prototypes learned during training. Prototypes were evaluated for interpretability by assessing differences in feature distributions and treatment-specific outcomes. A 3-prototype model achieved an AUC of 0.66 and an expected absolute improvement in population remission rate compared to the sample remission rate. We identified three treatment-relevant patient clusters which were clinically interpretable. It is possible to produce novel treatment-relevant patient profiles using machine learning models; doing so may improve precision medicine for depression. Note: This model is not currently the subject of any active clinical trials and is not intended for clinical use.
Applying Artificial Intelligence to Clinical Decision Support in Mental Health: What Have We Learned?
Mar 06, 2023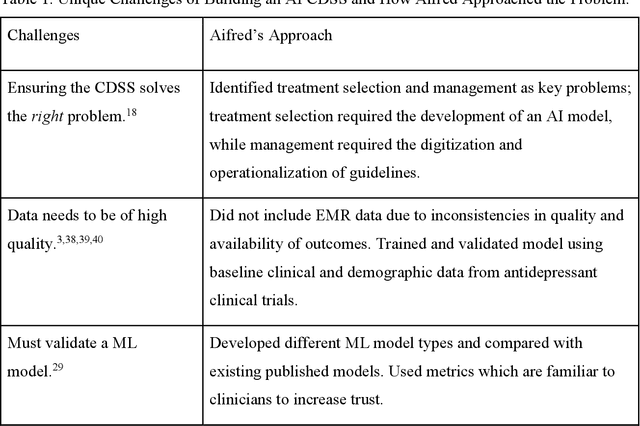
Clinical decision support systems (CDSS) augmented with artificial intelligence (AI) models are emerging as potentially valuable tools in healthcare. Despite their promise, the development and implementation of these systems typically encounter several barriers, hindering the potential for widespread adoption. Here we present a case study of a recently developed AI-CDSS, Aifred Health, aimed at supporting the selection and management of treatment in major depressive disorder. We consider both the principles espoused during development and testing of this AI-CDSS, as well as the practical solutions developed to facilitate implementation. We also propose recommendations to consider throughout the building, validation, training, and implementation process of an AI-CDSS. These recommendations include: identifying the key problem, selecting the type of machine learning approach based on this problem, determining the type of data required, determining the format required for a CDSS to provide clinical utility, gathering physician and patient feedback, and validating the tool across multiple settings. Finally, we explore the potential benefits of widespread adoption of these systems, while balancing these against implementation challenges such as ensuring systems do not disrupt the clinical workflow, and designing systems in a manner that engenders trust on the part of end users.
Big Data Analytics and AI in Mental Healthcare
Mar 12, 2019Mental health conditions cause a great deal of distress or impairment; depression alone will affect 11% of the world's population. The application of Artificial Intelligence (AI) and big-data technologies to mental health has great potential for personalizing treatment selection, prognosticating, monitoring for relapse, detecting and helping to prevent mental health conditions before they reach clinical-level symptomatology, and even delivering some treatments. However, unlike similar applications in other fields of medicine, there are several unique challenges in mental health applications which currently pose barriers towards the implementation of these technologies. Specifically, there are very few widely used or validated biomarkers in mental health, leading to a heavy reliance on patient and clinician derived questionnaire data as well as interpretation of new signals such as digital phenotyping. In addition, diagnosis also lacks the same objective 'gold standard' as in other conditions such as oncology, where clinicians and researchers can often rely on pathological analysis for confirmation of diagnosis. In this chapter we discuss the major opportunities, limitations and techniques used for improving mental healthcare through AI and big-data. We explore both the computational, clinical and ethical considerations and best practices as well as lay out the major researcher directions for the near future.