 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain to Me: Towards Understanding Privacy Decisions
Jan 05, 2023Privacy assistants help users manage their privacy online. Their tasks could vary from detecting privacy violations to recommending sharing actions for content that the user intends to share. Recent work on these tasks are promising and show that privacy assistants can successfully tackle them. However, for such privacy assistants to be employed by users, it is important that these assistants can explain their decisions to users. Accordingly, this paper develops a methodology to create explanations of privacy. The methodology is based on identifying important topics in a domain of interest, providing explanation schemes for decisions, and generating them automatically. We apply our proposed methodology on a real-world privacy data set, which contains images labeled as private or public to explain the labels. We evaluate our approach on a user study that depicts what factors are influential for users to find explanations useful.
SHACL Constraints with Inference Rules
Nov 01, 2019


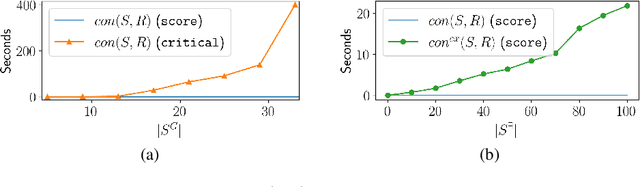
The Shapes Constraint Language (SHACL) has been recently introduced as a W3C recommendation to define constraints that can be validated against RDF graphs. Interactions of SHACL with other Semantic Web technologies, such as ontologies or reasoners, is a matter of ongoing research. In this paper we study the interaction of a subset of SHACL with inference rules expressed in datalog. On the one hand, SHACL constraints can be used to define a "schema" for graph datasets. On the other hand, inference rules can lead to the discovery of new facts that do not match the original schema. Given a set of SHACL constraints and a set of datalog rules, we present a method to detect which constraints could be violated by the application of the inference rules on some graph instance of the schema, and update the original schema, i.e, the set of SHACL constraints, in order to capture the new facts that can be inferred. We provide theoretical and experimental results of the various components of our approach.
Rule Applicability on RDF Triplestore Schemas
Jul 02, 2019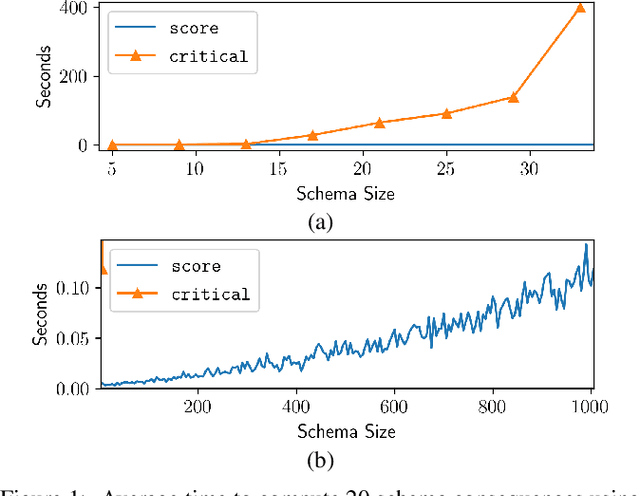
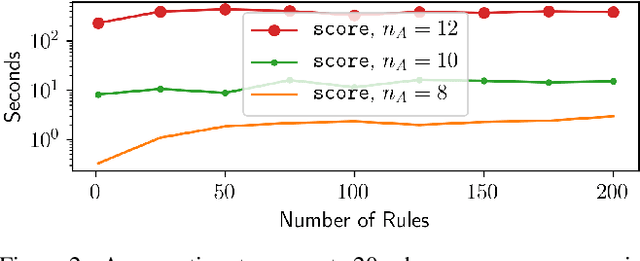
Rule-based systems play a critical role in health and safety, where policies created by experts are usually formalised as rules. When dealing with increasingly large and dynamic sources of data, as in the case of Internet of Things (IoT) applications, it becomes important not only to efficiently apply rules, but also to reason about their applicability on datasets confined by a certain schema. In this paper we define the notion of a triplestore schema which models a set of RDF graphs. Given a set of rules and such a schema as input we propose a method to determine rule applicability and produce output schemas. Output schemas model the graphs that would be obtained by running the rules on the graph models of the input schema. We present two approaches: one based on computing a canonical (critical) instance of the schema, and a novel approach based on query rewriting. We provide theoretical, complexity and evaluation results that show the superior efficiency of our rewriting approach.