 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking a Decade of Research at the University of Nigeria, Nsukka: A Scientometric Analysis (2014-2023)
May 22, 2026This study employs scientometric methods to assess the research output and performance of the University of Nigeria from 2014 to 2023. By analyzing publication trends, citation patterns, and collaboration networks, the research aims to comprehensively evaluate the university's research productivity, impact, and disciplinary focus. These research endeavors are characterized by innovation, interdisciplinary collaboration, and commitment to excellence, making the University of Nigeria a significant hub for cutting-edge research in Nigeria and beyond. The present study has been undertaken to determine the impact of the university's research and publication trends from 2014 to 2023. The study focuses on year-wise research output, citation impact at local and global levels, prominent authors and their total output, top journals, collaborating countries, and the most contributing departments of the University of Nigeria. The university's ten years of publication data indicate that 6,353 papers were published from 2014 to 2023, receiving 86,202 citations with an h-index of 39. In addition to this, the stenographical mapping of data is presented through graphs using the VOSviewer software mapping technique. The findings of this study will contribute to understanding the university's research strengths, weaknesses, and potential areas for improvement. Additionally, the results will inform evidence-based decision-making for enhancing research strategies and policies at the University of Nigeria
* 16 pages, 4 figures, Research Article
Mapping a Decade of Avian Influenza Research (2014-2023): A Scientometric Analysis from Web of Science
Feb 02, 2026This scientometric study analyzes Avian Influenza research from 2014 to 2023 using bibliographic data from the Web of Science database. We examined publication trends, sources, authorship, collaborative networks, document types, and geographical distribution to gain insights into the global research landscape. Results reveal a steady increase in publications, with high contributions from Chinese and American institutions. Journals such as PLoS One and the Journal of Virology published the highest number of studies, indicating their influence in this field. The most prolific institutions include the Chinese Academy of Sciences and the University of Hong Kong, while the College of Veterinary Medicine at South China Agricultural University emerged as the most productive department. China and the USA lead in publication volume, though developed nations like the United Kingdom and Germany exhibit a higher rate of international collaboration. "Articles" are the most common document type, constituting 84.6% of the total, while "Reviews" account for 7.6%. This study provides a comprehensive view of global trends in Avian Influenza research, emphasizing the need for collaborative efforts across borders.
* 24 pages, 7 figures, Research Article
Global research trends and collaborations in Fibrodysplasia Ossificans Progressiva: A bibliometric analysis (1989-2023)
Jan 07, 2026Fibrodysplasia Ossificans Progressiva (FOP) is a rare and debilitating genetic disorder characterized by the progressive formation of bone in muscles and connective tissues. This scientometric analysis examines the global research trends on FOP between 1989 and 2023 using bibliographic data from Web of Science. The study highlights key patterns in publication productivity, influential journals, institutions, and the geographical distribution of research. The findings reveal that the United States leads both in terms of total publications and citation impact, with significant contributions from the UK, Italy, Japan, and other European countries. Additionally, the analysis identifies the major document types, including articles and reviews, and evaluates the collaborative efforts across institutions. The study offers valuable insights into the global research landscape of FOP, providing a foundation for future studies and international collaborations.
Mapping Research Productivity of BRICS Countries with Special Reference to Coronary Artery Disease (CAD): A Scientometric Study
Nov 07, 2025This study presents a comprehensive scientometric analysis of research productivity on Coronary Artery Disease (CAD) among the BRICS countries, Brazil, Russia, India, China, and South Africa, using data retrieved from the Web of Science database for the period 1990 to 2019. A total of 50,036 records were analyzed to assess publication growth trends, authorship patterns, collaboration levels, and citation impact. The findings reveal a steady increase in CAD-related publications, with China emerging as the leading contributor, followed by Brazil, Russia, India, and South Africa. English dominated as the primary language of communication, accounting for over 93% of publications. Authorship and collaboration analysis indicate a high degree of joint research, with 97.91% of studies being co-authored and a degree of collaboration of 0.98, underscoring the collective nature of scientific inquiry in this domain. The study validates the applicability of Lotkas Law for author productivity, Bradfords Law for journal distribution, and Zipfs Law for keyword frequency, while the Price Square Root Law was found inapplicable. The predominant publication format was journal articles (79.7%), and Kardiologiya (Russia) emerged as the most prolific journal. The results demonstrate significant growth in CAD research output and collaboration within BRICS, though notable disparities persist among member nations. The study recommends enhancing individual author productivity, expanding international collaboration, and supporting CAD research through strategic institutional and governmental initiatives. These findings provide valuable insights for policymakers, funding agencies, and the academic community to strengthen cardiovascular research capacity within developing economies.
* 260 Pages, 21 figures, PhD Thesis 2020
Publication Trend in DESIDOC Journal of Library and Information Technology during 2013-2017: A Scientometric Approach
Nov 06, 2025DESIDOC Journal of Library & Information Technology (DJLIT) formerly known as DESIDOC Bulletin of Information Technology is a peer-reviewed, open access, bimonthly journal. This paper presents a Scientometric analysis of the DESIDOC Journal. The paper analyses the pattern of growth of the research output published in the journal, pattern of authorship, author productivity, and, subjects covered to the papers over the period (2013-2017). It is found that 227 papers were published during the period of study (2001-2012). The maximum numbers of articles were collaborative in nature. The subject concentration of the journal noted is Scientometrics. The maximum numbers of articles (65%) have ranged their thought contents between 6 and 10 pages. The study applied standard formula and statistical tools to bring out the factual result.
* 7 pages, 3 figures, Research Article
Two Decades of Research at the University of Lagos (2004-2023): A Scientometric Analysis of Productivity, Collaboration, and Impact
Nov 06, 2025This paper presents a scientometric analysis of research output from the University of Lagos, focusing on the two decades spanning 2004 to 2023. Using bibliometric data retrieved from the Web of Science, we examine trends in publication volume, collaboration patterns, citation impact, and the most prolific authors, departments, and research domains at the university. The study reveals a consistent increase in research productivity, with the highest publication output recorded in 2023. Health Sciences, Engineering, and Social Sciences are identified as dominant fields, reflecting the university's interdisciplinary research strengths. Collaborative efforts, both locally and internationally, show a positive correlation with higher citation impact, with the United States and the United Kingdom being the leading international collaborators. Notably, open-access publications account for a significant portion of the university's research output, enhancing visibility and citation rates. The findings offer valuable insights into the university's research performance over the past two decades, providing a foundation for strategic planning and policy formulation to foster research excellence and global impact.
* 19 pages, 3 figures, Research Article
Research Output of Webology Journal (2013-2017): A Scientometric Analysis
Oct 31, 2025Webology is an international peer-reviewed journal in English devoted to the field of the World Wide Web and serves as a forum for discussion and experimentation. It serves as a forum for new research in information dissemination and communication processes in general, and in the context of the World Wide Web in particular. This paper presents a Scientometric analysis of the Webology Journal. The paper analyses the pattern of growth of the research output published in the journal, pattern of authorship, author productivity, and subjects covered to the papers over the period (2013-2017). It is found that 62 papers were published during the period of study (2013-2017). The maximum numbers of articles were collaborative in nature. The subject concentration of the journal noted was Social Networking/Web 2.0/Library 2.0 and Scientometrics or Bibliometrics. Iranian researchers contributed the maximum number of articles (37.10%). The study applied standard formula and statistical tools to bring out the factual result.
* 13 pages, 3 figures, Research Paper
Identifying and Mapping the Global Research Output on Coronavirus Disease: A Scientometric Study
Feb 19, 2021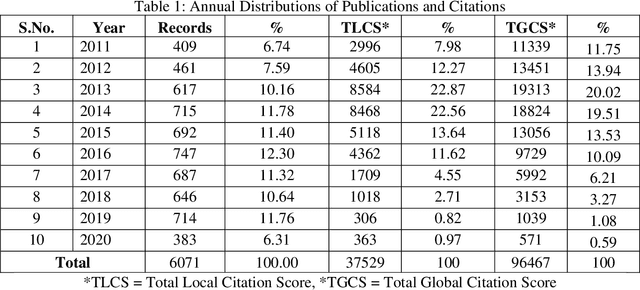
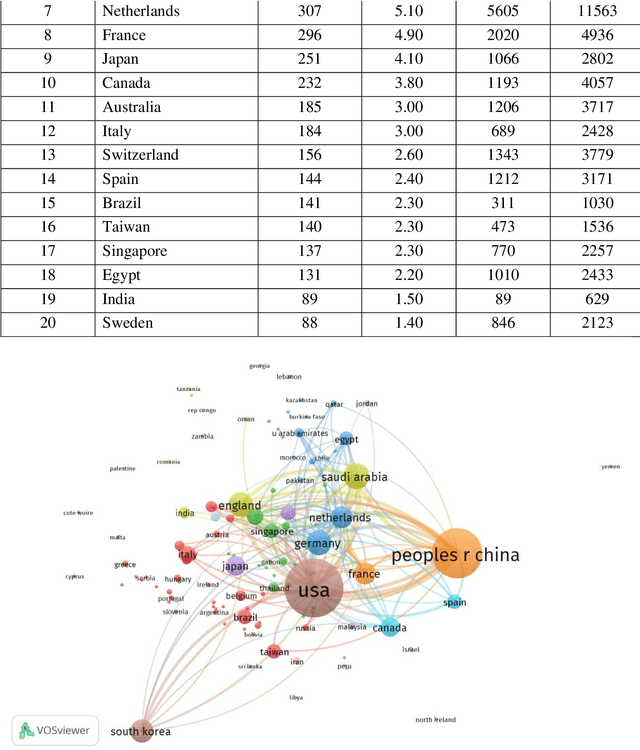
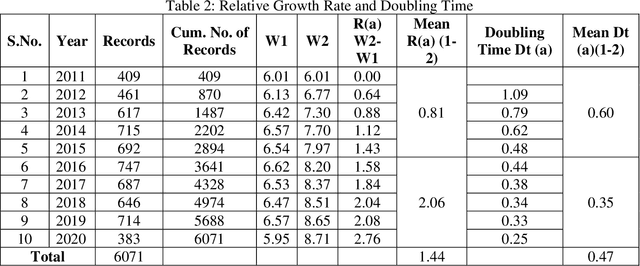
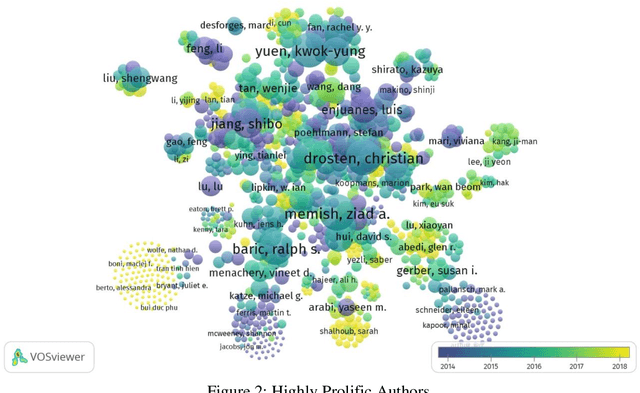
The paper explores and analyses the trend of world literature on "Coronavirus Disease" in terms of the output of research publications as indexed in the Science Citation Index Expanded (SCI-E) of Web of Science during the period from 2011 to 2020. The study found that 6071 research records have been published on Coronavirus Disease till March 20, 2020. The various scientometric components of the research records published in the study period were studied. The study reveals the various aspects of Coronavirus Disease literature such as year wise distribution, relative growth rate, doubling time of literature, geographical wise, organization wise, language wise, form wise , most prolific authors, and source wise. The highest number of articles was published in the year 2019, while lowest numbers of research article were reported in the year 2020. Further, the relative growth rate is gradually increases and on the other hand doubling time decreases. Most of the research publications are published in English language and most of the publications published in the form of research articles. USA is the highest contributor to the field of Coronavirus Disease literature.
Testing Lotka's Law and Pattern of Author Productivity in the Scholarly Publications of Artificial Intelligence
Feb 18, 2021Artificial intelligence has changed our day to day life in multitude ways. AI technology is rearing itself as a driving force to be reckoned with in the largest industries in the world. AI has already engulfed our educational system, our businesses and our financial establishments. The future is definite that machines with artificial intelligence will soon be captivating over trained manual work that now is mostly cared by humans. Machines can carry out human-like tasks by new inputs as artificial intelligence makes it possible for machines to learn from experience. AI data from web of science database from 2008 to 2017 have been mapped to depict the average growth rate, relative growth rate, contribution made by authors in the view of research productivity, authorship pattern and collaboration of AI literature. The Lotka's law on authorship productivity of AI literature has been tested to confirm the applicability of the law to the present data set. A K-S test was applied to measure the degree of agreement between the distribution of the observed set of data against the inverse general power relationship and the theoretical value of {\alpha} =2. It is found that the inverse square law of Lotka follow as such.
* 17 Pages
Competition vs. Concatenation in Skip Connections of Fully Convolutional Networks
Jul 20, 2018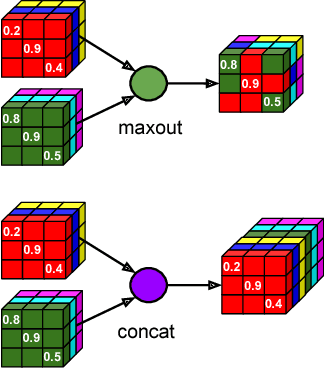
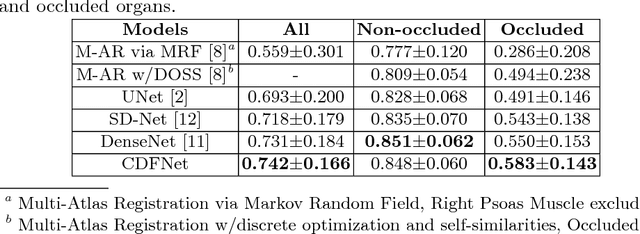
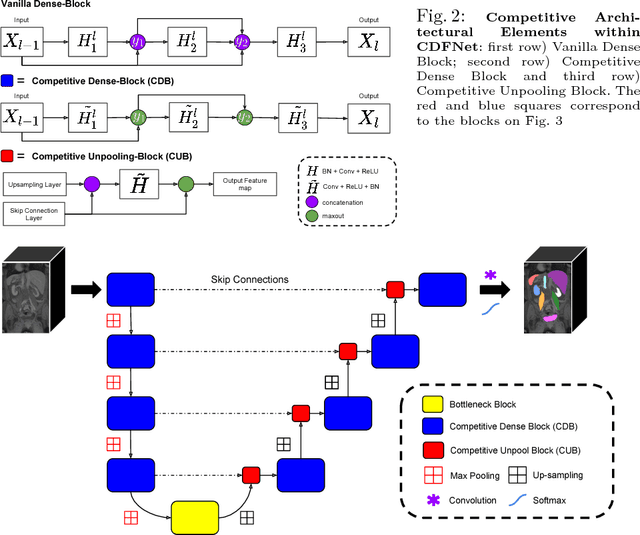
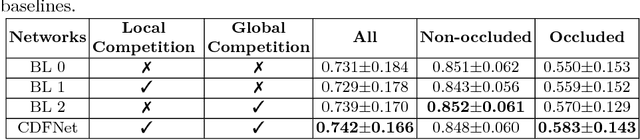
Increased information sharing through short and long-range skip connections between layers in fully convolutional networks have demonstrated significant improvement in performance for semantic segmentation. In this paper, we propose Competitive Dense Fully Convolutional Networks (CDFNet) by introducing competitive maxout activations in place of naive feature concatenation for inducing competition amongst layers. Within CDFNet, we propose two architectural contributions, namely competitive dense block (CDB) and competitive unpooling block (CUB) to induce competition at local and global scales for short and long-range skip connections respectively. This extension is demonstrated to boost learning of specialized sub-networks targeted at segmenting specific anatomies, which in turn eases the training of complex tasks. We present the proof-of-concept on the challenging task of whole body segmentation in the publicly available VISCERAL benchmark and demonstrate improved performance over multiple learning and registration based state-of-the-art methods.