 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAWAII: Hierarchical Visual Knowledge Transfer for Efficient Vision-Language Models
Jun 23, 2025Improving the visual understanding ability of vision-language models (VLMs) is crucial for enhancing their performance across various tasks. While using multiple pretrained visual experts has shown great promise, it often incurs significant computational costs during training and inference. To address this challenge, we propose HAWAII, a novel framework that distills knowledge from multiple visual experts into a single vision encoder, enabling it to inherit the complementary strengths of several experts with minimal computational overhead. To mitigate conflicts among different teachers and switch between different teacher-specific knowledge, instead of using a fixed set of adapters for multiple teachers, we propose to use teacher-specific Low-Rank Adaptation (LoRA) adapters with a corresponding router. Each adapter is aligned with a specific teacher, avoiding noisy guidance during distillation. To enable efficient knowledge distillation, we propose fine-grained and coarse-grained distillation. At the fine-grained level, token importance scores are employed to emphasize the most informative tokens from each teacher adaptively. At the coarse-grained level, we summarize the knowledge from multiple teachers and transfer it to the student using a set of general-knowledge LoRA adapters with a router. Extensive experiments on various vision-language tasks demonstrate the superiority of HAWAII, compared to the popular open-source VLMs.
LEO-MINI: An Efficient Multimodal Large Language Model using Conditional Token Reduction and Mixture of Multi-Modal Experts
Apr 07, 2025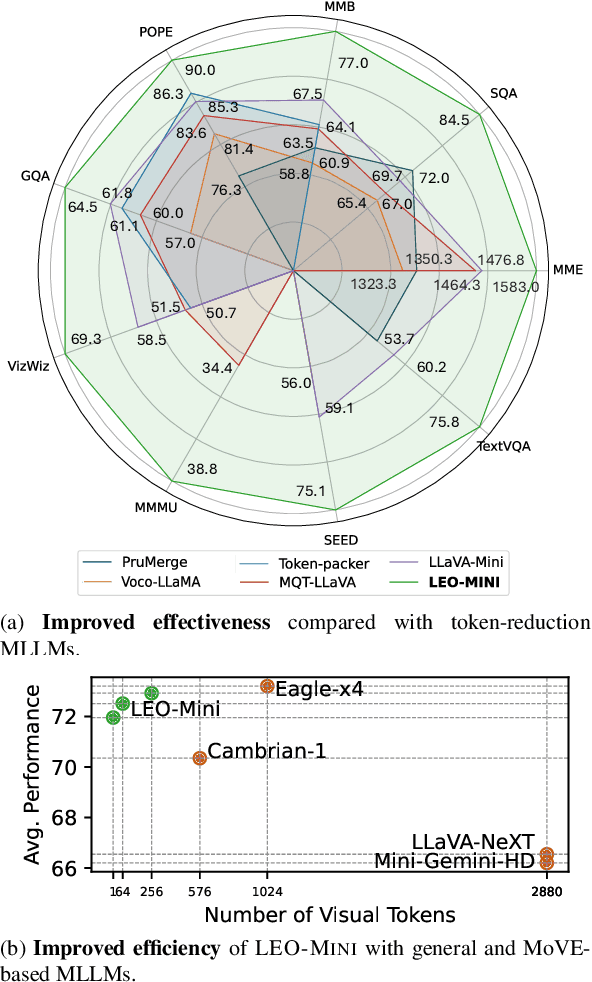

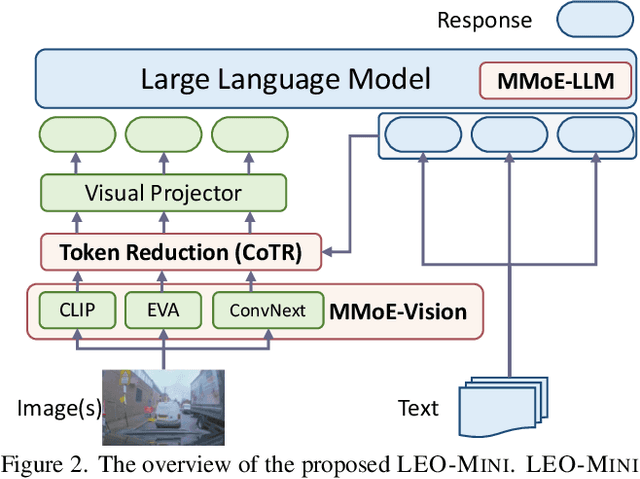
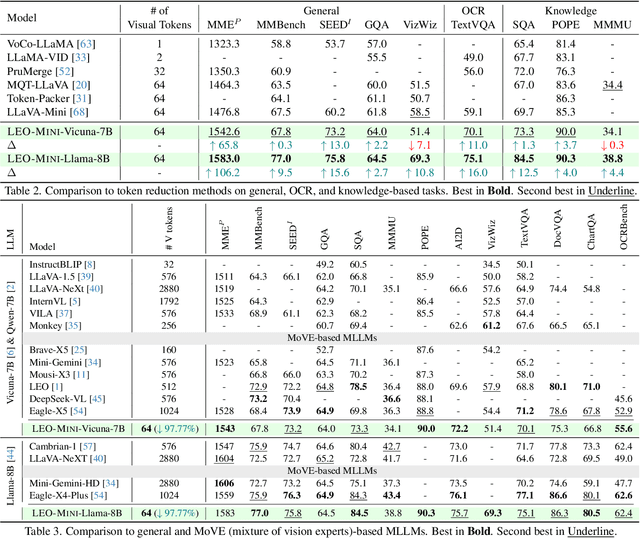
Redundancy of visual tokens in multi-modal large language models (MLLMs) significantly reduces their computational efficiency. Recent approaches, such as resamplers and summarizers, have sought to reduce the number of visual tokens, but at the cost of visual reasoning ability. To address this, we propose LEO-MINI, a novel MLLM that significantly reduces the number of visual tokens and simultaneously boosts visual reasoning capabilities. For efficiency, LEO-MINI incorporates CoTR, a novel token reduction module to consolidate a large number of visual tokens into a smaller set of tokens, using the similarity between visual tokens, text tokens, and a compact learnable query. For effectiveness, to scale up the model's ability with minimal computational overhead, LEO-MINI employs MMoE, a novel mixture of multi-modal experts module. MMOE employs a set of LoRA experts with a novel router to switch between them based on the input text and visual tokens instead of only using the input hidden state. MMoE also includes a general LoRA expert that is always activated to learn general knowledge for LLM reasoning. For extracting richer visual features, MMOE employs a set of vision experts trained on diverse domain-specific data. To demonstrate LEO-MINI's improved efficiency and performance, we evaluate it against existing efficient MLLMs on various benchmark vision-language tasks.
LEO: Boosting Mixture of Vision Encoders for Multimodal Large Language Models
Jan 13, 2025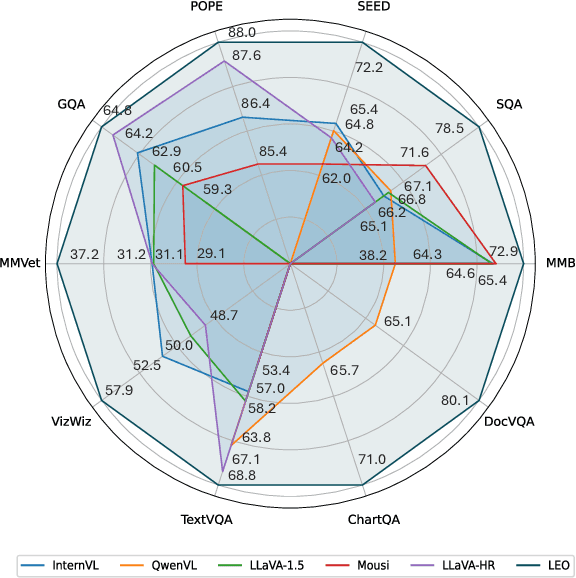
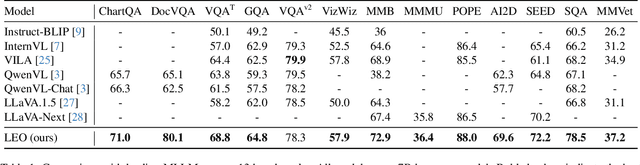
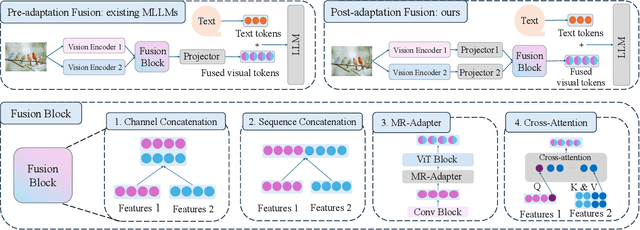

Enhanced visual understanding serves as a cornerstone for multimodal large language models (MLLMs). Recent hybrid MLLMs incorporate a mixture of vision experts to address the limitations of using a single vision encoder and excessively long visual tokens. Despite the progress of these MLLMs, a research gap remains in effectively integrating diverse vision encoders. This work explores fusion strategies of visual tokens for hybrid MLLMs, leading to the design of LEO, a novel MLLM with a dual-branch vision encoder framework that incorporates a post-adaptation fusion strategy and adaptive tiling: for each segmented tile of the input images, LEO sequentially interleaves the visual tokens from its two vision encoders. Extensive evaluation across 13 vision-language benchmarks reveals that LEO outperforms state-of-the-art open-source MLLMs and hybrid MLLMs on the majority of tasks. Furthermore, we show that LEO can be adapted to the specialized domain of autonomous driving without altering the model architecture or training recipe, achieving competitive performance compared to existing baselines. The code and model will be publicly available.